-
[Parquet] 파케이 파일 내부 구조 및 동작 방식 파악Software Development/Data Engineering 2025. 12. 30. 02:42
Parquet는 오픈소스이고 데이터 저장과 검색에 효율적인 컬럼기반 데이터 파일 포맷이다. 높은 압축률과 인코딩을 제공하며 많은 프로그래밍 언어와 분석 툴을 지원한다.[1]
이 정도의 내용은 대부분 알려진 사실이다. 다만 이번에 파케이 파일의 내부 구조를 깊이 알아보게 된 계기는 단순 Parquet 파일에 데이터를 저장하는 것이 '높은 압축률과 인코딩'을 제공하지만 다루는 도구(Spark, Flink, Trino, ...) 따라서 편차가 있다는 것을 알게 되었기 때문이다.
Parquet 파일을 다룰 때 Hive Table, Iceberg Table과 같은 테이블 형식으로 다루게 되는데 이때 기본적으로 스몰파일을 핸들링하기 위한 파티셔닝, 버켓팅과 같은 전략에 대해서는 많이 알려져있다.
그러나 파케이 파일 포맷을 지원하고 그리고 Write가 동작한다고 해서 같은 결과를 내는 것이 아닌 것을 알았고 이는 관련 도구 및 생태계가 얼마나 파케이 파일의 특성과 내부적인 매커니즘을 잘 소화하냐에 따라서 달라진다는 것을 배웠기 때문이다.
이번 글을 통해서 Parquet 파일의 매커니즘과 관련 생태계 도구들을 알아보고 왜 이러한 결과 차이가 나는지 알아가고자 한다.
parquet-format
우선 들어가기에 앞서 간단하게 파케이 파일의 내부 구조에 대해서 들여다 보고자 한다.
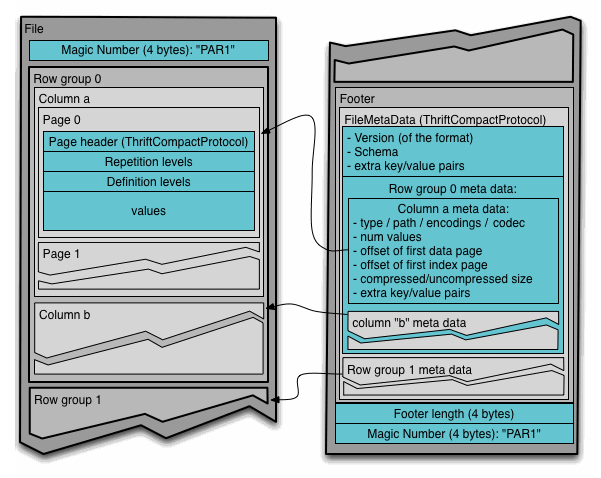
[2] 파일의 구조를 살펴보면 다음과 같은 덩어리로 나눌 수 있다.
- File: 파일에 대한 메타데이터를 포함하는 파일이다.
- Row group: 데이터를 Row 단위로 분할한 논리적인 구조이다. Row를 분할하는 물리적인 구조는 없다. Row Group은 컬럼 청크로 구성되어 있다.
- Column chunk: 특정 컬럼에 대한 덩어리다. 파일 내에서 반드시 연속적으로 배치된다.
- Page: 컬럼 청크는 다시 Page라는 단위로 나뉜다. Page는 압축과 인코딩관점에서 더 이상 나눌 수 없는 단위이다.
- Footer: 파일에 대한 메타데이터를 저장하고 있다. Row Group 단위로 Version, Schema, Extra key/value Pairs가 저장된다. Column chunk에 대해 type, path, encodings, codes, offset, compressed/uncompressed size 등이 저장된다.
파케이 파일의 병렬 처리 단위에 대해서 알아보고자 한다.
File/Row Group - 분산처리 엔진에서 파케이 파일을 MapReduce하는 단위이다. 즉 계산하는 단위라 보면 되겠다.
IO - Column chunk 단위로 가져온다. 특정 열만 선택해서 읽는 단위라 보면 되겠다.
Page - 압축 해제와 인코딩은 페이지 단위로 수행한다.
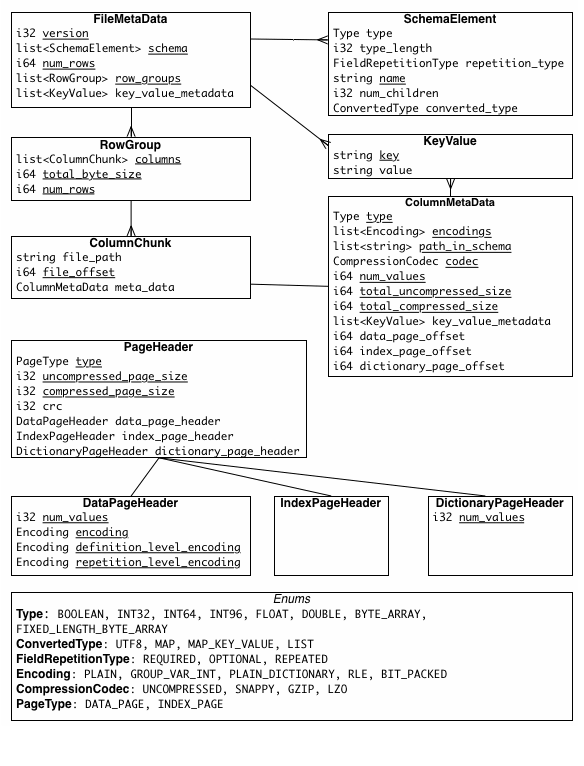
파케이의 메타데이터에 대해서 알아보자.
메타데이터는 File Metadata와 Page Header Metadata가 있다.
File Metadata는 스키마, row count, row_groups, key_value_metadata에는 컬럼에 대한 메타데이터를 저장한다.
Page Header는 비압축 페이지 사이즈, 압축 페이지 사이즈 등이 저장된다.
Page Header의 DataPageHeader에는 행의 개수, 인코딩 방식, 통계값을 저장한다.
Nested Column을 인코딩하기 위해서 Dremel Encoding[3]을 사용하는데 이때 definition_level_encoding 과 repetition_level_encoding를 사용한다.
/** Data page header */ struct DataPageHeader { /** * Number of values, including NULLs, in this data page. * * If a OffsetIndex is present, a page must begin at a row * boundary (repetition_level = 0). Otherwise, pages may begin * within a row (repetition_level > 0). **/ 1: required i32 num_values /** Encoding used for this data page **/ 2: required Encoding encoding /** Encoding used for definition levels **/ 3: required Encoding definition_level_encoding; /** Encoding used for repetition levels **/ 4: required Encoding repetition_level_encoding; /** Optional statistics for the data in this page **/ 5: optional Statistics statistics; }IndexPageHeader: TODO
Page Header의 DictionaryPageHeader는 Dictionary Encoding 사용시 생성되는 헤더이다. 사전 데이터에 포함된 고유 값의 개수(num_values)와 인코딩 방식이 기록된다.
[2] Null 값 처리는 어떻게 할까?
Null 여부는 정의 수준(definition levels)에 인코딩되며, run-length encoded, RLE) 방식을 사용한다. NULL 값 자체는 데이터 영역에 별도로 인코딩되어 저장않는다.
예를 들어, 중첩되지 않은 단순 스키마에서 1,000개의 NULL 값을 가진 컬럼은 정의 수준에서 0이 1,000번 반복된다는 정보로 인코딩될 뿐, 그 외의 데이터는 아무것도 저장되지 않는다.
Encodings
Plain Encoding: Parquet에서 지원하는 가장 기본적이고 단순한 인코딩 방식이다. 인코딩/디코딩 과정에서 CPU 연산이 거의 필요 없다. 읽고 쓰는 속도가 매우 빠르다. 모든 데이터 타입에 적용 가능하다.
보통 Parquet은 보통 처음에는 Dictionary Encoding을 시도한다. 하지만 다음과 같은 상황이 발생하면 Plain Encoding으로 전환(Fallback)한다.
- 중복이 거의 없는 경우: 모든 값이 고유하다면 사전을 만드는 것이 오히려 용량만 낭비
- 사전이 너무 커지는 경우: 고유 값의 개수가 설정된 임계치를 넘어가면 "사전 방식이 비효율적이다"라고 판단하여 Plain 방식으로 저장
Dictionary Encoding: 특정 컬럼에서 발견되는 값들로 사전을 구축한다. 컬럼 청크(column chunk)당 하나의 딕셔너리 페이지에 저장한다.
Run Length Encoding / Bit-Packing Hybrid (RLE = 3): RLE encoding 방식은 아래의 데이터 타입에 대해서만 지원한다.
- Repetition and definition levels
- Dictionary indices
- Boolean values in data pages, as an alternative to PLAIN encoding
즉 Dictionary Encoding을 먼저 적용하고 그 결과물인 '인덱스 번호'들을 저장할 때 RLE/Bit-Packing Hybrid를 사용한다.
RLE, Bit-Packing를 어떻게 적용하는지 순서를 알아보자.
값을 8개씩 나눠서 똑같은 값이 연속해서 나온다면 Run Length Encoding을 적용한다.
값들이 서로 다르지만, 숫자의 크기(범위)가 작다면 Bit-Packing을 적용한다.
헤더 표시: 이 뭉치가 어떤 모드인지 알려주는 '헤더 비트'를 앞에 붙인다. 헤더의 마지막 비트가 0이면 RLE, 1이면 Bit-Packing이다.
아래와 같은 데이터가 있다면 RLE를 먼저 적용한다.
[0, 0, 0, 0, 0, 0, 0, 0, 1, 2, 0, 3, 1, 1, 2, 0]아래는 RLE 인코딩 적용한다. 연속 동일 값 8개, 같은 값이 8번 연속되면 RLE run으로 전환한다.[4]
[0, 0, 0, 0, 0, 0, 0, 0]public void writeInt(int value) throws IOException { if (value == previousValue) { // keep track of how many times we've seen this value // consecutively ++repeatCount; if (repeatCount >= 8) { // we've seen this at least 8 times, we're // certainly going to write an rle-run, // so just keep on counting repeats for now return; } } else { // This is a new value, check if it signals the end of // an rle-run if (repeatCount >= 8) { // it does! write an rle-run writeRleRun(); } // this is a new value so we've only seen it once repeatCount = 1; // start tracking this value for repeats previousValue = value; } // We have not seen enough repeats to justify an rle-run yet, // so buffer this value in case we decide to write a bit-packed-run bufferedValues[numBufferedValues] = value; ++numBufferedValues; if (numBufferedValues == 8) { // we've encountered less than 8 repeated values, so // either start a new bit-packed-run or append to the // current bit-packed-run writeOrAppendBitPackedRun(); } }아래는 Bit-Packing 인코딩 적용한다.
[1, 2, 0, 3, 1, 1, 2, 0]아래의 예제를 살펴보자.
dec value: 0 1 2 3 4 5 6 7 bit value: 000 001 010 011 100 101 110 111 bit label: ABC DEF GHI JKL MNO PQR STU VWXbit value: 10001000 11000110 11111010 bit label: HIDEFABC RMNOJKLG VWXSTUPQPLAIN: 8개 데이터 * 4byte = 32바이트
Hybrid: 헤더 1바이트(bitWidth) + 패킹 데이터 3바이트 = 4바이트
이상 파케이 파일에 대해서 알아보았다.
여기서 원래의 질문으로 돌아가서 '처리 엔진마다 Write가 동작한다고 해서 같은 결과를 내는 것이 아닌 것'에 대해서 얘기하고자 한다.
다른 결과, 차이가 날 수 있는 포인트는 어디일까?
크게 Compression과 Encoding이라 볼 수 있다.
단, Compression의 경우 Table Properties를 통해 설정되어 있고 ZSTD를 사용하고 압축레벨도 같았기 때문에 큰 차이가 없다고 볼 수 있다. 그러면 Encoding에서 차이가 날 수 있는데 데이터 자체에 대한 Encoding은 Dictionary Encoding만 확인하면 된다.
Dictionary Encoding의 기본 사이즈는 다음과 같다.
public static final int PARQUET_DICT_SIZE_BYTES_DEFAULT = 2 * 1024 * 1024; // 2 MB2MB이며 이를 초과하면 Fallback Logic으로 Plain Encoding을 실행하게 된다. PARQUET_DICT_SIZE_BYTES_DEFAULT의 설정에 따라 인코딩 사이즈가 달라지고 고카디널리티 컬럼에 대해서는 2MB가 넘기 때문에 Plain Encoding으로 넘어갈 수 있다.
다만, PARQUET_DICT_SIZE_BYTES_DEFAULT를 따로 설정하지 않았기 때문에
다른 데이터 처리 엔진을 사용하더라고 2MB를 기본값으로 사용하게 되면 같은 결과가 나와야 한다.
그러면 Parquet file의 물리 데이터 사이즈가 다른 이유는 무엇 때문일까? 같은 row_count를 가지고 있으며 같은 Property를 참고하는데 어떻게 다를 수 있을까?
이에 대한 답은 분산처리의 정렬과 관련이 있을 수 있다.
Spark Iceberg Writer의 코드를 살펴보자
[5] SparkWrite.java
@Override public SortOrder[] requiredOrdering() { return writeRequirements.ordering(); }SparkWriteRequirements.java[6]
public class SparkWriteRequirements { public static final SparkWriteRequirements EMPTY = new SparkWriteRequirements(Distributions.unspecified(), new SortOrder[0]); private final Distribution distribution; private final SortOrder[] ordering; SparkWriteRequirements(Distribution distribution, SortOrder[] ordering) { this.distribution = distribution; this.ordering = ordering; } public Distribution distribution() { return distribution; } public SortOrder[] ordering() { return ordering; } public boolean hasOrdering() { return ordering.length != 0; } }SparkWriteUtil.java[7]
private static SortOrder[] writeOrdering(Table table, boolean fanoutEnabled) { if (fanoutEnabled && table.sortOrder().isUnsorted()) { return EMPTY_ORDERING; } else { return ordering(table); } } private static Expression[] clustering(Table table) { return Spark3Util.toTransforms(table.spec()); } private static SortOrder[] ordering(Table table) { return Spark3Util.toOrdering(SortOrderUtil.buildSortOrder(table)); }Spark3Util.java [8]
public static SortOrder[] toOrdering(org.apache.iceberg.SortOrder sortOrder) { SortOrderToSpark visitor = new SortOrderToSpark(sortOrder.schema()); List<SortOrder> ordering = SortOrderVisitor.visit(sortOrder, visitor); return ordering.toArray(new SortOrder[0]); }SortOrderUtil.java [9]
public static SortOrder buildSortOrder(Schema schema, PartitionSpec spec, SortOrder sortOrder) { if (sortOrder.isUnsorted() && spec.isUnpartitioned()) { return SortOrder.unsorted(); } // make a map of the partition fields that need to be included in the clustering produced by the // sort order Map<Pair<String, Integer>, PartitionField> requiredClusteringFields = requiredClusteringFields(spec); // remove any partition fields that are clustered by the sort order by iterating over a prefix // in the sort order. // this will stop when a non-partition field is found, or when the sort field only satisfies the // partition field. for (SortField sortField : sortOrder.fields()) { Pair<String, Integer> sourceAndTransform = Pair.of(sortField.transform().toString(), sortField.sourceId()); if (requiredClusteringFields.containsKey(sourceAndTransform)) { requiredClusteringFields.remove(sourceAndTransform); continue; // keep processing the prefix } // if the field satisfies the order of any partition fields, also remove them before stopping // use a set to avoid concurrent modification for (PartitionField field : spec.fields()) { if (sortField.sourceId() == field.sourceId() && sortField.transform().satisfiesOrderOf(field.transform())) { requiredClusteringFields.remove(Pair.of(field.transform().toString(), field.sourceId())); } } break; } // build a sort prefix of partition fields that are not already in the sort order's prefix SortOrder.Builder builder = SortOrder.builderFor(schema); for (PartitionField field : requiredClusteringFields.values()) { String sourceName = schema.findColumnName(field.sourceId()); builder.asc(Expressions.transform(sourceName, field.transform())); } // add the configured sort to the partition spec prefix sort SortOrderVisitor.visit(sortOrder, new CopySortOrderFields(builder)); return builder.build(); }SortOrderUtil.java의 buildSortOrder 메서드를 보면
정렬 설정도 없고, 파티션도 설정되지 않은 테이블이라면 정렬할 필요가 없으므로 즉시 unsorted를 반환한다.
그리고 파티션키를 SortOrder에 반드시 추가하고 있다.
그리고 아이스버그 테이블 버전 1.2.0 이후 write.distribution-mode의 기본값은 hash로 파티션 키를 기준으로 데이터를 셔플하여 같은 파티션은 같은 Task로 모은다. 이렇게 되면 특수한 상황이 아니라면 하나의 파티션당 하나의 Task로 Rolling으로 파일을 쓰게 된다.
Trino Iceberg Writer의 코드를 살펴보자
Trino에서 Iceberg Write는 크게 Planning, Execution/PageSink, Commit 단계로 이루어진다.
그리고 Trino의 간단한 데이터 처리 구조에 대해서 알아보자.
Coordinator가 쿼리를 받아서 Planning을 한다. 이에 따라 여러개의 Stage로 쿼리를 나눈다. 이때 Spark의 Stage와 다른 점은 Trino의 Stage는 병렬로 실행될 수 있다는 점이다. 그리고 Stage는 여러 Task로 나눠진다. Task는 하나의 Worker에 바인딩된다. Task는 여러 Split을 처리한다.
Page는 Trino 내부에서 데이터를 이동하는 단위이다. Task ↔ Task간의 데이터 이동이라 보면된다.
TableScan → Page 생성, Filter / Project → Page 변환, Exchange → Page 전송
Block은 Page의 하나의 컬럼에 해당한다. 즉, Page는 여러 Block으로 구성된다.
IcebergPageSink.java - 데이터가 들어오면 어떤 파티션인지 계산하고, 해당 파티션의 Writer에게 데이터를 넘겨준다.[10]
@Override public CompletableFuture<?> appendPage(Page page) { doAppend(page); return NOT_BLOCKED; } private void doAppend(Page page) { int writeOffset = 0; while (writeOffset < page.getPositionCount()) { Page chunk = page.getRegion(writeOffset, min(page.getPositionCount() - writeOffset, MAX_PAGE_POSITIONS)); writeOffset += chunk.getPositionCount(); writePage(chunk); } } private void writePage(Page page) { int[] writerIndexes = getWriterIndexes(page); // position count for each writer int[] sizes = new int[writers.size()]; for (int index : writerIndexes) { sizes[index]++; } // record which positions are used by which writer int[][] writerPositions = new int[writers.size()][]; int[] counts = new int[writers.size()]; for (int position = 0; position < page.getPositionCount(); position++) { int index = writerIndexes[position]; int count = counts[index]; if (count == 0) { writerPositions[index] = new int[sizes[index]]; } writerPositions[index][count] = position; counts[index]++; } // invoke the writers for (int index = 0; index < writerPositions.length; index++) { int[] positions = writerPositions[index]; if (positions == null) { continue; } // if write is partitioned across multiple writers, filter page using dictionary blocks Page pageForWriter = page; if (positions.length != page.getPositionCount()) { verify(positions.length == counts[index]); pageForWriter = pageForWriter.getPositions(positions, 0, positions.length); } WriteContext writeContext = writers.get(index); verify(writeContext != null, "Expected writer at index %s", index); IcebergFileWriter writer = writeContext.getWriter(); long currentWritten = writer.getWrittenBytes(); long currentMemory = writer.getMemoryUsage(); writer.appendRows(pageForWriter); writtenBytes += (writer.getWrittenBytes() - currentWritten); memoryUsage += (writer.getMemoryUsage() - currentMemory); // Mark this writer as active (i.e. not idle) activeWriters.set(index, true); } } private int[] getWriterIndexes(Page page) { int[] writerIndexes = pagePartitioner.partitionPage(page); // expand writers list to new size while (writers.size() <= pagePartitioner.getMaxIndex()) { writers.add(null); activeWriters.add(false); } // create missing writers for (int position = 0; position < page.getPositionCount(); position++) { int writerIndex = writerIndexes[position]; WriteContext writer = writers.get(writerIndex); if (writer != null) { if (writer.getWrittenBytes() <= targetMaxFileSize) { continue; } closeWriter(writerIndex); } Optional<PartitionData> partitionData = getPartitionData(pagePartitioner.getColumns(), page, position); // prepend query id to a file name so we can determine which files were written by which query. This is needed for opportunistic cleanup of extra files // which may be present for successfully completing query in presence of failure recovery mechanisms. String fileName = fileFormat.toIceberg().addExtension(session.getQueryId() + "-" + randomUUID()); String outputPath = partitionData .map(partition -> locationProvider.newDataLocation(partitionSpec, partition, fileName)) .orElseGet(() -> locationProvider.newDataLocation(fileName)); if (!sortOrder.isEmpty() && sortedWritingEnabled) { String tempName = "sorting-file-writer-%s-%s".formatted(session.getQueryId(), randomUUID()); Location tempFilePrefix = tempDirectory.appendPath(tempName); WriteContext writerContext = createWriter(outputPath, partitionData); IcebergFileWriter sortedFileWriter = new IcebergSortingFileWriter( fileSystem, tempFilePrefix, writerContext.getWriter(), sortingFileWriterBufferSize, sortingFileWriterMaxOpenFiles, columnTypes, sortColumnIndexes, sortOrders, pageSorter, typeManager.getTypeOperators()); writer = new WriteContext(sortedFileWriter, outputPath, partitionData); } else { writer = createWriter(outputPath, partitionData); } writers.set(writerIndex, writer); currentOpenWriters++; memoryUsage += writer.getWriter().getMemoryUsage(); } verify(writers.size() == pagePartitioner.getMaxIndex() + 1); if (currentOpenWriters > maxOpenWriters) { throw new TrinoException(ICEBERG_TOO_MANY_OPEN_PARTITIONS, format("Exceeded limit of %s open writers for partitions: %s", maxOpenWriters, currentOpenWriters)); } return writerIndexes; }위 코드에서 getWriterIndexes(page);가 파티션 로직이다. 각 Row가 어떤 Writer로 가야하는지 결과를 받아온다.
Page의 데이터를 읽어 파티션을 계산하고, 해당 파티션을 담당하는 Writer가 없으면 새로 만들고 Writer Indexes를 반환한다.
writePage 메서드에서 가져온 WriterIndexes에 대해서 page에 WriterIndex에 해당하는 pageForWriter를 구해서 appendRows를 실행한다.
appendRows는 내부적으로 sorting하여 저장한다.[11]
@Override public void appendRows(Page page) { if (!sortBuffer.canAdd(page)) { flushToTempFile(); } sortBuffer.add(page); } @Override public Closeable commit() { flushed = true; Closeable rollbackAction = createRollbackAction(fileSystem, tempFiles); if (!sortBuffer.isEmpty()) { // skip temporary files entirely if the total output size is small if (tempFiles.isEmpty()) { sortBuffer.flushTo(outputWriter::appendRows); outputWriter.commit(); return rollbackAction; } flushToTempFile(); } try { writeSorted(); outputWriter.commit(); } catch (UncheckedIOException e) { throw new TrinoException(HIVE_WRITER_CLOSE_ERROR, "Error committing write to Hive", e); } return rollbackAction; }Spark, Trino의 Parquet File Write에 대해서 알아보았다. 어떤 차이가 있을까?
Spark의 write.distribution-mode의 hash로 인해서 파티션 키를 기준으로 데이터를 셔플하여 같은 파티션은 같은 Task로 모은다. 그리고 이때 파티션 키를 기준으로 정렬을 실행한다. 이후에 Write가 Rolling으로 동작하기 때문에 파티션 키 기준으로 정렬된 상태의 Parquet File이 저장된다.
Trino의 경우 Page는 Task ↔ Task 간의 데이터 이동이다. 즉, 워커에서 다른 워커로 데이터를 전달할 때 Page를 전달하게 되는데 이때 Page는 정렬되어 있을까?
Page가 appendRows를 통해서 저장될 때는 정렬을 진행한다. 이 부분을 자세히 들여다 보면 sortBuffer에 Page의 데이터를 저장하고 가득차면 temp file에 flush한다. 그리고 commit할 때 writeSorted 메서드를 통해서 combineFiles 메서드를 실행하여 파일은 전부 합친다.
여기서 writer가 받는 page는 정렬되어 있지않다. page가 정렬되어 있지 않기 때문에 Rolling하며 파케이 파일을 저장할 때 해당 파일에 대해서는 정렬이 될 것이다. 그러나 파일끼리의 정렬은 되어 있지 않은 상태가 된다.
즉, 파일 A,B,C,D,E가 partition_key dt이고 '2025-12-31' 파티션에 여러 파일이 존재한다면
A,B,C,D,E의 dt 'min/max'가 모두 '2025-12-31 00:00:00/2025-12-31 23:59:59'가 될 수 있다는 것이다.
이에 따라서 Dictionary encoding의 결과가 많이 달라질 수 있게 된다. 왜냐하면 같은 구간에 같은 값이 몰려있다면 Dictionary encoding의 효과가 미비할 수 있다.
그리고 Dictionary encoding의 PARQUET_DICT_SIZE_BYTES_DEFAULT를 초과하면 Plain Encoding을 적용하기 때문에 이에 따라서 인코딩 효율이 떨어질 수 있다.
Trino에서 인코딩 효율이 떨어지는 문제 이를 해결할 수 있을까? 결론은 어렵다.
이를 위해서는 Page가 전역적으로 정렬이 된 상태를 유지해야 한다. Trino는 Upstream Task에서 Page가 생성되는 대로 Downstream Task(Writer 쪽)로 즉시 보낸다. 여러 워커노드에서 동시에 Page를 보내기 때문에 Writer 입장에서는 A 노드에서 온 Page와 B 노드에서 온 Page가 뒤섞여서 들어오게 된다.
Spark의 경우 RDD를 기반으로 완벽히 정렬된 데이터셋이 있을 것이고 이를 기반으로 순차적으로 데이터를 적재한다면 완벽하게 파일끼리 정렬된 상태로 파일들을 저장할 수 있다.
References
[1] https://parquet.apache.org/docs/overview/
[2] https://github.com/apache/parquet-format
[3] https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/36632.pdf
'Software Development > Data Engineering' 카테고리의 다른 글
[Pinot] Apache Pinot 조사 (0) 2025.02.01 [Flink] 플링크 공부 (0) 2025.01.27 [Kafka] 단일 파티션에 대한 고민 (0) 2024.05.27 [Spark] Spark JDBC와 하이브 연동 이슈들. (0) 2023.05.05 [Hive] 하이브 테이블에 Spark으로 적재 시, HQL로 읽을 때, 값이 Null로 조회되는 이슈. (0) 2023.05.02