-
[ADsP 정리] 3.데이터 분석Study/자격증 2020. 3. 10. 12:56
R기초와 데이터 마트
R 패키지 사용하기
- R에서 패키지는 함수, 데이터, 코드, 문서 등을 묶은 것을 의미
- R은 오픈 소스 프로그램으로 다양한 기능이 패키지가 존재
- 패키지를 사용하는 데 필요한 함수 install().pakages(),library()
- install().pakage("패키지 이름): vozlwlfmf ekdnsfhemgotj tjfclgksek.
- library(패키지 이름) or library("패키지 이름"): 패키지를 로드하여 사용할 준비를 한다.
R 연산자(산술, 할당, 비교, 논리)
R 산술 연산자
- 산술 연산자의 우선순위: 괄호 -> 거듭제곱, 곱하기, 나누기 -> 더하기, 빼기
주의: 동일한 우선순위의 경우 왼쪽에서 오른쪽 순서를 가짐연산자 설명 예 결과 + 더하기 3+2 5 - 빼기 3-2 1 * 곱하기 3*2 6 / 나누기 3/2 1.5 ^or ** 승수 3^2 9 R 할당 연산자
- 어떤 객체의 이름을 특정한 값에 저장할 때 사용
연산자 설명 입력내용 결과 <-, = 오른쪽의 값을 왼쪽의 이름에 저장 x<-3. x=3 동일한 값 3 R 비교연산자
- 두 개 값에 대한 비교로서 맞으면 TRUE, 맞지 않으면 FALSE 값을 갖는다.
연산자 설명 입력내용 결과값 > 크다 3>4 FALSE >= 크거나 같다 3>=4 FALSE == 같다 3==4 FALSE ! 부정 !(3==4) TRUE 주의: 연산자 안에 공백이 있으면 안된다. 예) "> ="
R 논리 연산자
- 두 개 이상의 조건을 비교하여 결과값을 출력
&
- AND의 개념
- 두 개의 조건을 동시에 만족할 때만 TRUE가 되는 논리 연산
- 예) TRUE&FALSE의 결과값은 FALSE
|
- OR의 개념
- 두 개의 조건 중에서 하나만 만족하여도 TRUE가 되는 논리 연산
- 예) TRUE&FALSE의 결과값은 TRUE
R 데이터 종류
통계 변수 범주형 명목형 혈액형 R factor 순서형 학점 factor 수치형 이산형 수강수 integer 연속형 키,몸무게 numeric 벡터
- 벡터는 동일한 데이터 유형으로 이루어진 한 개 이상의 값들로 구성
- 하나의 열로 구성
- 벡터는 데이터 분석의 가장 기본 단위임
벡터의 속성을 확인하는 함수
- 벡터가 가지는 각각의 값을 '원소(Element)'라 한다.
- 원소가 어떤 데이터 유형, 개수, 이름을 나타내는 것을 속성이라 한다.
- mode(벡터): 데이터 유형을 알려줌.
- is.numeric(벡터): 데이터 유형이 numeric이 맞으면 TRUE 아니면 FALSE
- is.logical(벡터): 데이터 유형이 logical이 맞으면 TRUE 아니면 FALSE
- is.charater(벡터): 데이터 유형이 charater가 맞으면 TRUE 아니면 FALSE
- length(): 원소의 개수, length와 nrow() 함수도 행렬과 데이터 프레임에서 행의 수를 알려준다 단 벡터에서는 대문자 NROW()를 사용한다.
변수이름 규칙
- R의 변수명(객체이름)은 알파벳, 숫자, _(언더스코어), .(마침표) 가능
- -(하이픈) 사용할 수 없다.
- 첫 글자는 알파벳 또는 .(마침표)로 시작. .(마침표) 뒤에는 숫자가 올 수 없다.
벡터의 연산
벡터의 길이가 동일한 경우
- 벡터들 간의 사칙연산이 가능 최종 결과는 벡터
- 벡터들 간의 연산이 될 때 동일한 위치의 값들 간에 연산
예) x <-(1,2,3), y<-(4,5,6)
적용 x+y x*y x/y 결과 5 7 9 4 10 18 0.25 0.40 0.50 벡터들 길이가 동일하지 않은 경우
- 두 벡터의 원수 개수가 다르더라도 연산과정에서 원소의 개수가 적은 쪽의 벡터는 원소 개수가 많은 쪽의 벡터와 동일학 원소의 개수를 맞춘다.
예) x<-(1,2,3) y<-(1,2,3,4,5,6) x+y = 2 4 6 7 9
행렬
- 행렬은 데이터의 형태가 2차원으로행과 열로 구성
- 벡터와 동일하게 하나의 테이터 유형만 가능
1. 생성 함수
- matrix(): nrow(행의 개수 지정), ncol(열의 개수 지정)
byrow(행렬에 값을 입력할 때 열 방향을 먼저 입력, 갑의 입력 방향을 행 방향으로 수정할 때는 TRUE 지정하고 사용함)
- rbind(): 벡터를 행 방향으로 합치는 방법 'r' = row
- cbind(): 벡터를 열 방향으로 합치는 방법 'c' = column
데이터 프레임
- 엑셀의 스프레드시트와 같은 2차원 데이터 구조
- R에서 가장 중요한 데이터 타입
- 여러 가지 데이터 유형을 가질 수 있음
- 통계에서 변수가 모여 집합자료가 되듯이 R에서도 벡터가 모여 데이터 프레임이 된다. 데이터 분석은 변수의 종류에 따라 분석 방법이 다르다.
1 데이터 프레임 생성함수
data.frame(): stringAsFactors(문자열을 factor로 저장할 것인지, 문자열로 저장할지 정하는 인자. 기본값은 TRUE)
str(): R 데이터 구조를 확인한다(행의 개수, 열의 개수, 변수명 데이터의 유형을 확인 가능).
리스트
- 서로 다른 데이터 타입을 담을 수 있음
- 리스트에 저장된 데이터는 색인 또는 키를 사용해 접근
- list() 함수 이용
array(배열)
- 행렬이 2차원 데이터라면 배열은 다차원 데이터이다.
데이터 마트 vs 데이터 웨어하우스
데이터 마트는 데이터 웨어하우스에 있는 일부 데이터를 가지고 특정 사용자를 대상으로 한다.
데이터 웨어하우스는 데이터를 쌓아놓는 곳이다. 데이터를 통합하고 정제해서 가장 핑료한 데이터들만 최소 비용으로 최적화되어 있지 않고 비효율적으로 배치된 상태이다.
그래서 사용하기 쉽게 시스템에 최적화하고 사람이 알기 쉽게 변환하고 성능 면에서 효율적으로 모아놓는 곳이 데이터 마트이다.
결측값의 대치법
결측/무응답을 가진 자료를 무시하지 않고 분석할 수 있는 통계 방법론의 하나인 대치법
1. 완전히 응답한 개체분석: 불완전 자료는 모두 무시하고 완전하게 관측된 자료만으로 표준적 통계기법에 의해 분석하는 방법
2. 평균댗법: 관측 또는 얻어진 자료의 적절한 평균값으로 결측값을 대치해서 불완전한 자료를 완전한 자료로 만든 후, 완전한 자료를 마치 관측 또는 실험되어 얻어진 자료라 생각하고 분석하는 방법
3. 단순확률 대치법:평균대치법에서 추정향 표준오차의 과소추정 문제를 보완하고자 고안된 방법
4. 다중대치법: 결측치를 가진 자료 분석에 사용하기가 용이하고, 통계적 추론에 사용된 통계량의 효율성 및 일치성 등의 문제를부분적으로 보완해준다.
이상값 검색
1. 이상값은 의도하지 않게 잘못 입력된 경우
2. 의도하지 않게 입력됐으나 분석 목적에 부합되지 않아 제거해야 하는 경우(Bad data)
3. 의도되지 않은 현상이지만 분석에 포함해야 하는 경우(이상값)
4. 의도된 이상값(아웃라이어) --->사기
# 관련 알고리즘 ESD(평균으로부터 3*표준편차 밖의 값을 이상치)
# 상자그림(boxplot) IQR*1.5 밖의 값을 이상치
# 일반적으로 summary() 평균과 중앙값과 IQR을 보고 판단
-> 결과적으로 이상값도 분석 대상이 될 수 있어 무조건 삭제는 안 됨
통계 부석
확률적 표본추출
1. 단순 무작위추출(simple random sampling): 모집단의 각 개체가 표본으로 선택될 확률이 동일하게 추출되는 경우이다. 모집단의 개체 수가 N 중에서 임의로 n(표본 수)개를 선택한다면, 개별 개체가 선택될 확률은 모두 n/N으로 일정하다.
2. 계통추출(systematic sampling): 모집단의 개체에 1, 2, ..., N이라는 일변번호를 부여한 후, 첫 번째 표본을 임의로 선택하고 일정 간격으로 다음 표본을 선택한다.
3. 층화추출(stratified sampling): 모집단을 성격에 따라 몇 개의 집단 또는 층으로 나누고, 각 집단 내에서 원하는 크기의 표본을 무작위로 추출한다.
4. 군집추출(cluster sampling): 모집단을 특성에 따라 여러 개의 집단으로 나눈다. 이들 집단 중에서 몇 개를 선택한 후, 선택된 집단 내에서 필요한 만큼의 표본을 임의로 선택한다.
척도(Scale)
1. 명목척도(nominal scale): 단순히 측정 대상의 특성을 분류하거나 확인하기 위한 목적으로 숫자 부여(성별)
2. 서열척도(ordinal scale): 단순히 대소 또는 높고 낮음 등의 순위만 제공할 뿐 양적인 비교는 할 수 없음(선호순위 1, 2, 3 순위)
3. 등간척도(interval scale): 순위를 부여하되 순위 사이의 간격이 동일하여 양적인 비교가 가능, 단 정대 0점이 존재하지 않음(온도계 수치, 물가지수, Likert 척도)
4. 비율척도(ratio scale): 절대0점이 존재하여 측정값 사이의 비율 계산이 가능한 척도(몸무게)
조건부확률과 독립사건
조건부확률(Conditional probability): 사건 B가 일어났다는 조건 아래서 사건 A가 일어날 조건부확률 P(B|A)와 같이 표시하고, 다음과 같이 정의한다.
P(A|B) = P(A∩B)/P(B), 단 P(B)>0
확률변수의 기댓갑과 분산
X가 확률 분포 f(x)를 갖는 확률변수라 하면, 기댓값은 아래와 같다.
- X가 이산적 확률변수의 기댓값 E(X) = Σxf(x)
- X가 연속적 확률변수의 기댓값 E(X) = ∫xf(x)
제1종 오류 vs 제2종 오류
- 제1종 오류(α error): 귀무가설 H0가 옳은데도 불구 하고 H0를 기각하게 되는 오류
- 제2종 오류(β error): 귀무가설 H0가 옳지 않은데도 불구 하고 H0를 채택하게 되는 오류
가설검정에서는 두 가지 오류가 작을수록 바람지가나 두 가지를 동시에 줄일 수 없기 때문에 제 1종오류를 범할 확률의 최대 허용치를 미리 어떤 특정한 값으로 지정해놓고 제 2종오류의 확률을 가장 작게 해주는 검정 방법을 택하게 된다.
유의확률 vs 유의수준
- 유의확률(significance probability): 관측된 검정통계량의 값보다 더 대립가설을 지지하는 검정통계량이 나올 확률
- 유의수준(significance level): 귀무가설이 맞는데 잘못해서 기각할 확률(제1종오류) 최댓값
모수적 검정
모수적 통계의 전제조건
1. 표본의 모집단이 정규분포를 이루어야 한다.
2. 집단 내의 분산은 같아야 한다.
3. 변인은 등간척도나 비율척도로 측정되어야 한다.
-> 이 조건이 충족되지 않으면 비모수 통계를 사용
모수 검정방법의 사용 예
1. 모평균과 표본평균과의 차이 -> z 분포, t 분포
2. 표본평균 간의 차이 -> z 분포, t 분포
3. 모분산과 표본분산과의 차이 -> F분포, 카이제곱분포
4. 표본분산 간의 차이 -.> F 분포, 카이제곱분포모수적 검정 VS 비모수적 검정
비교대상 집단 수 관계 비모수 모수 단일 표본 분석 sign test(Binomial test 이용) T test Kolmogorov-Smirnov test 2표본 독립 Mann-Whitney T test 대응 자료 Wilcoxon 부호-서열 test Paired T test K표본 독립 Kruskal-Wallis H test ANOVA test 대응 료 Friedman test 모수적 추론 VS 비모수적 추론 VS 베이지안 추론 비교
모수적 추론
(parametric inference)
비모수적 추론
(non-parametric inference)
베이지안 추론
(Bayesian inference)
모집단에 특정 분포를 가정하고 분포의 특성을 결정하는 모수에 대해 추론(추정, 가설검정)하는 방법 - 모집단에 대한 분포가정을 하지 않음
- 모집단의 특성을 몇 개의 모수로 결정하기 어려우며 수많은 모수가 필요할 수 있음
모수를 상수가 아닌 확률변수로 봄->확률분포를 가짐
- 사후분포(posterir distribution)를 유도
회귀모형에 대한 가정
1. 선형선(독립변수의 변화에 따라 종속변수도 변화하는 선형(linear)인 모형이다.)
2. 독립성(잔차와 독립변수의 값이 관련돼 있지 않는다.) -> Durbin-waston 검정을 통해 확인 가능
3. 등분산성(오차항들의 분포는 동일한 분산을 갖는다.)
4. 비상관성(잔차들끼리 상관이 없어야 함
5. 정상성(잔차항이 정규분포를 이뤄야 함)
다중회귀분석 해석하기
1. 모형이 통계적으로 유의미한가? F 분포와 유의확률(p-value)로 확인한다.
2. 회귀계수들이 유의미한가? 회귀계수의 t값과 유의확률(p-value)로 확인한다.
3. 모형이 얼마나 설명력을 갖는가? 결정 계수를 확인한다.
4. 모형이 데이터를 잘 적합하고 있는가? 잔차통계량을 확인하고 회귀진단을 한다.
잔차분석
1. Noraml Q-Q 잔차가 정규분포를 잘 따르고 있는지 확인하는 그래프이다. 잔차들이 그래프 선상에 있어야 이상적이다.
2. Scale-Location은 y축이 표준화 잔차를 나타낸다. 이 역시 기울기 0인 직선이 이상적이다.
3. Cook's Distance는 일반적으로 1값이 넘어가면 관측치를 영향점(Influence points)으로 판별
다중공선성(Multicolinearity)
모형의 일부 예측 변수가 다른 예측 변수와 상관되어 있을 때 발생하는 조건이다. 중대한 다중공선성은 회귀계수의 분산을 증가시켜 불안정하고 해석하기 어렵게 만들기 때문에 문제가 된다.
회귀분석 단계적 변수 선택(Stepwise Variable Selection)
1. 후진제거법(Backward Elimination): 모든 변수가 포함된 모델에서 기준 통계치에 가장 도움이 되지 않는 변수를 하나씩 제거하는 방법
2. 전진선택법(Forward Selection): 절편만 있는 모델에서 기준 통계치를 가장 많이 개선시키는 변수를 차례로 추가하는 방법
3. 단계별 방법(stepwise method): 전진선택법에 의해 변수를 추가하면서 새롭게 추가된 변수에 기인해 기존 변수가 그 중요도가 약화되면 해당 변수를 제거하는 등 단계별로 추가 또는 제거되는 변수의 여부를 검토해 더 이상 없을 때 중단한다.
정규화 선형회귀(Regularized Linear Regression)
정규화 선형회ㅟ 방법은 선형회귀 계수에 대한 제약 조건을 추가함으로써 모형이 과도하게 최적화되는 현상, 즉 과적합(overfitting)를 막는 방법이다.
릿지회귀 VS 라쏘회귀 VS 엘라스틱넷 비교
구분 릿지회귀 라쏘회귀 엘라스틱넷 제약식 norm norm +norm 변수선택 불가능 가능 가능 장점 변수 간 상관관계가 높아도 좋은 성능 변수 간 상관관계가 높으면 성능이 떨어짐 변수 간 상관관계를 반영한 정규화 상관분석
구분 사용 척도 분석 방법 상관분석 서역철도 스피어만 상관분석 등간척도, 비율척도 피어슨 상관분석 편상관분석 상관분석 검정
cor.test() 함수를 사용해 상관계수 검정을 수행하여 상관계수의 유의성 검정을 판단할 수 있다. 이때 귀무가설은 '상관계수가 0이다', 대립가설은 '상관계수가 0이 아니다'.
피어슨 상관계수 Vs 스피어만 상관계수 비교
피어슨 상관계수 스피어만 상관계수 1. 피어슨의 상관계수는 두 변수 간의 선형관계의 크기를 측정하는 값으로 비선형적인 상관관계는 나타내지 못한다.
2. 연속형 변수만 가능
3.예) 국어 점수와 영어 점수와의 상관계수
1. 스피어만 상관계수는 두 변수 간의 비선형적인 관계도 나타낼 수 있다.
2. 연속형 외에 이산형 순서형도 가능
3. 국어 성적 석차와 영어 성적 석차의 상관계수
상관분석에서 결측치 다루기
원본데이터에 NA셀이 하나라도 있으면, 결과로 나오는 상관행렬에도 NA값들이 생긴다.
이는 use="complete.obs"는 na.rm-T 같은 의미 또는 use="pairwise.cimplete.obs" 관측치 자체르 빼지않고 NA가 포함된 벡터만 제외하다는 의미 옵션을 사용해 해결된다.
결정계수
1. 회귀의 분산분석에서 총제곱합(총변동, SSr) = 회귀제곱합(설명된 변동, SSR) + 오차제곱합(설명 안 된 변동, SSE)이며, SSR은 추정회귀방정식에 의해 설명되는 부분이다.
2. R^2(결정계수) = 회귀제곱합(SSR) / 총제곱합(SST)
다차원척도법(Multidimensional Scaling, MDS)
다차원척도법은 개체들 사이의 유사성 / 비유사성을 측정하여 2차원 또는 3차원 공간상에 표현하는 분석 방법으로 개체들 간의 근접성을 시각화하여 데이터 속에 잠재해 있는 패던이나 구조를 찾아내는 통계기법
차원축소 목표를 이루기 위해 개발된 분석 방법
1. 주성분분석(Principal Component Analysis)
2. 요인분석(Factor Analysis)
3. 판별분석(Discriminant Analysis)
4. 군집분석(Cluster Analysis)
5. 정준상관분석(Canoninal Correlation Analysis)
6. 다차원척도법(Multi-dimensional Scaling) 등이 있다.
주성분분석(PCA, Principal Component Analysis) 목적
분서갈 때 변수의 개수가 많다고 모두 활용하는 것이 꼭 좋은 것은 아니다.
오히려 변수 간 다중공선성이 있을 경우 분석 결과에 영향을 줄 수도 있다.
따라서 많은 변수들을 한 번에 쓰기보다는 정보의 손실을 최소화하고 다른 몇 개의 성분으로 달리 표현해 분석 한다면 위의 문제들을 피할 수 있다. 결국 차원축소를 한다는 의미이다.
주성분분석할 때 고민해야 하는 것
- 상관행렬과 공분산행렬 중 어느 것을 선택할 것인가?
- 공분산행렬이 default 설정, 따라서 상관행렬 이용 시 cor=TRUE 변경 설정
- 주성분의 개수를 몇개로 할 것인가?
- 주성분에 영향을 미치는 변수로 어떤 변수를 선택할 것인가?
공분산행렬 VS 상관행렬
주성분분석의 문제는 척도에 영향을 받는다는점이다. 변수들의 선형결합을 유도할 때 분산을 이용하기 때문에 결과적으로 공분산행렬로부터 유도된 주성분은 측정 단위의 크기에 좌우된다.
설문조사처럼 모든 변수들이 같은 수준으로 점수화가 된 경우에는 공분산행렬을 사용해도 되지만 변수들들의 scale이 서로 많이 다른 경우에는 값이 큰 특정 변수가 전체적인 경행을 좌우하기 때문에 상관계수행렬을 사용하여 추출해야 한다.
-> 공분산행렬(covariance matrix)과 상관계수행렬(correlation matrix)의 고유값과 고유벡터가 일반적으로 동일하지 않을 수 있으므로 주성분이 달라질 수 있음
주성분분석의 아이젠벡터(고유벡터) 아이젠밸류(고유값)
주성분분석에서 고유값 = 분산의 크기
i번째 주성분의 고유값 / 전체 고유값 = 데이터 전체 분산 중 i번째 주성분이 가지는 분산(%)
주성분분석 주성분 수 결정
정보손실을 최소화하는 방법과 주성분의 분산을 최대화하는 방법이며, 누적기여율과 고유치 값은 주성분의 수를 결정하는 기준. 일반적으로 고유치 값이 1.0이상, 누적기여율이 80% 되는 주성분을 기준으로 주성분 수를 결정한다.
정상시계열
1. 평균값은 시간 t에 관계없이 일정하다.
2. 분산값은 시간 t에 관계없이 일정하다.
3. 공분산은 시간 t에 의존하지 않고 오직 시차에만 의존한다.
비정상시계열을 정상시계열로 전환하는 방법
1. 시계열의 평균이 일정하지 않은 경우에는 원시계열에 차분하면 정상시계열이 된다.
2. 계절성을 갖는 비정상시계열은 정상시계열로 바꿀 때 계절차분을 사용한다.
3. 분산이 일정하지 않은 경우에는 원계열에 자연로그(변환)를 취하면 정상시계열이 된다.
백색잡음 과정
시계열 et의 평균이 0이고 분산이 일정한 값 시그마^2 이고 자기공분산이 0인 경우 이를 백색잡음 과정이라고 함(회귀 분석 오차항의 기본 과정과 유사한 개념으로 생각하자.)
시계열 모형
1. AR 모형: 자기회귀모형은 현 시점의 시계열 자료에 몇 번째 전 자료까지 영향을 주는지 알아내는 데 있다. 현 시점의 시계열 자료에 과거 1시점 이전의 자료만 영향을 준다면, 이를 1차 자기회귀모형이라고 하며 AR(1) 모형이라 한다.
2. MA 모형: 현 시점의 자료를 유한 개의 백색잡음의 선형결합으로 표현되었기 때문에 항상 정상성을 만족한다. 이동평균모형은 자귀회귀모형과 반대로 자기상관함수 p+1 시차 이후 절단된 형태를 취한다.
3. 자기회귀 노적이동모형(ARIMA): 대부분의 많은 시계열 자료가 자기회귀 누적이동평균모형을 따른다. ARIMA 모형은 기본적으로 비정상시계열 모형이기 때문에 차분이나 변환을 통해 AR, MA, ARMA 모형으로 정상화 할 수 있다.시계열 모형 식별하기
자기회귀 이동평균 자귀회귀이동평균 자기상관함수 지수적 감소 q+1차항부터 절단 모양 q+1차항부터 지수적 감소 편자기함수 p+1차항부터 절단 모양 지수적 감소 p+1차항부터 지수적 감소 분해시계열
시계열에 영향을 주는 일반적인 요인을 시계열에서 분리해 분석하는 방법
1. 추세요인: 자료가 어떤 특정한 형태를 취할 때 추세요인이라 한다.
2. 계절요인: 계절에 따라 고정된 주기에 따라 자료가 변화할 경우 계절요인이라 한다.
3. 순환요인: 알려지지 않은 주기를 가지고 자료가 변화할 때 순환요인이라 한다.
4. 불규칙요인: 위 세가지 요인으로 설명할 수 없는 회귀분석에서 오차에 해당하는 요인을 불규칙요인이라고 한다.
정형 데이터 마이닝
대표적 데이터 마이닝 기법
1. 분류(Classification): 분류기법으로는 의사결정나무(decision tree), memory-based reasoning 등이 있다.
2. 추정(Esatimation): 추정기법으로는 신경망 모형이 있다.
3. 예측(Prediction): 입력 데이터의 성격에 따라 장바구니 분석, 의사결정나무, 신경망 등이 예측 기법으로 사용된다.
4. 연관분석(Association Analysis): 장바구니 분석이라고도한다.
5. 군집(Clustering): 미리 정의된 기준이나 예시에 의해서가 아닌 레코드 자체가 지니고 있는 다른 레코드와의 유사성에 의해 그룹화되고 이질성에 의해 세분화된다.
6. 기술(Description)
데이터 마이닝 5단계(데이터 준비, 데이터 가공, 데이터마이닝 기법 적용 내용 비교)
1. 목적 정의
2. 데이터 준비: 데이터 정제를 통해 데이터의 품질 보장, 필요시 데이터 양을 충분히 확보
3. 데이터 가공: 모델링 목적에 따라 목적변수 정의 데이터마이닝 소프트웨어 적용이 가능하도록 가공 충분한 cpu와 메모리, 디스크 공간 등 개발환경 구축이 선행
4. 데이터 마이닝 기법 적용: 모델을 목적에 맞게 선택하고 소프트웨어를 사용하는 데 필요한 값 지정 단계
5. 검증
로지스틱 회귀모형 오즈(odds)
오즈 =성공률/실패률=P/(1-P) 단, P는 성공률
오즈는 음이 아닌 실수값으로 성공이 일어날 가능성이 높은 경우에는 1.0보다 큰 값을, 반대로 실패가 일어날 가능성이 높은 경우에는 1.0보다 작은 값을 가지게 된다.
-> 기준이 1보다 크면 증가 1보다 작으면 감소
선형회귀분석 VS 로지스틱 회귀분석 비교
일반서녕 회귀분석 로지스틱 회귀분석 종속변수 연속형 변수 이산형 변수 모형 탐색 방법 최소자승법 최대우도법, 가중최소자승법 모형 검정 F-test, t-test x^2 test 로지스틱 회귀계수의 해석
coef(b)
(Intercept) Sepal.Length
-27.831451 5.140336(회귀계수)
# 로지스틱 회귀계수 값은 exp(5.140336)의 값이므로 약 170이 된다.
신경망 모형이란?
신경망은 입력층, 은닉층, 출력층 3개의 층으로 구성되어 있고 각 층에는 뉴런이 몇 개씩 포함되어 있음. 은닉층의 수와 은닉층 내 노드수, 반복 학습 수는 연구자가 지정
복잡한 모형일수록 적합도는 향상되나 분석과정 소요시간이 많이 걸림
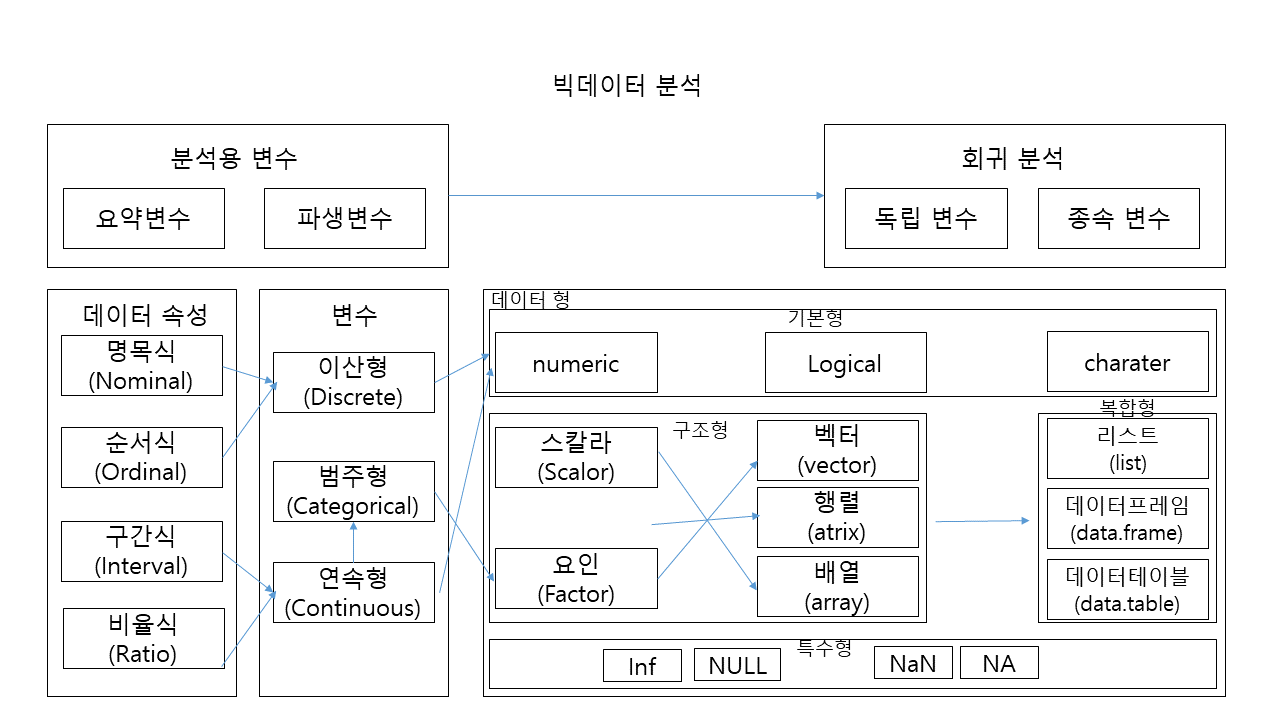
신경망 활성화 함수(Activation Function)
https://towardsdatascience.com/activation-functions-and-its-types-which-is-better-a9a5310cc8f 여기서 활성화 함수로 결과값을 내보낼 때 사용하는 함수로 가중치 값을 학습할 때 에러가 적게 나도록 도와줌. 주요 활성화 함수로는 계단 함수, 부호 함수, 시그모이드 함수, 소프트맥스 있음
신경망의 은닉층 및 은닉 노드 수를 정할 때 고려사항
1. 다층신경망은 단층신경망에 비해 훈련이 어렵다.
2. 노드가 많을수록 복잡성을 잡아내기 쉽지만, 과적합의 가능성도 높아진다
3. 은닉층 노드가 너무 적으면 복잡한 의샂결정 경계를 만들 수 없다.
신경망 모형의 장점 VS 단점
장점 단점 변수의 수가 많거나 입,출력변수 간에 복잡한 비선형 관계 유용 결과에 대한 해석이 쉽지 않다.
잡음에 대해서도 민감하게 반응하지 않는다. 최적의 모형을 도출하는 것이 상대적으로 어려움 입력변수와 결과변수가 연속형이나 이산형인 경우 모두 처리가능 데이터 정규화를 하지 않으면, 지역해에 빠질 위험이 있다. 의사결정나무 모형의 분리 기준
1. 지니지수: 불순도를 측정하는 지수로서 이 지니지수를 가장 적게 잠소시켜 주는 예측변수와 이때의 최적분리에 의해 자식마디를 선택한다.

https://www.kdnuggets.com/2019/02/decision-trees-introduction.html/2 
https://www.kdnuggets.com/2019/02/decision-trees-introduction.html/2 2. 엔트로피 지수(Entropy measure)
엔트로피 지수가 가장 작은 예측 변수와 이떄의 최적분리에 의해 자식마디를 형성함
3. 가이제곱 통계량의 유의확률
카이제곱 검정에 기반을 둔 것으로서 목표변수가 범주형일 때 Pearson의 가이제곱 통계량을 분리기준을 사용함
의사결정나무의 결정 규칙
분할규칙 VS 정지규칙 VS 가지치기 규칙
분할규칙(spliting rule) 정지규칙(stopping rule) 가지치기 규칙(pruning rule) 새 가지를 어디서부터 나오게 할까? 어떤 기준을 만족하면 새 가지가 더 이상 나오지 못하게 하도록 하는가? 어느 가지를 쳐내야 예측력이 좋은 나무가 될까? 목표변수가 범주형인 경우
C5.0은 언트로피 지수,
CART은 지니지수,
CHAID는 카이제곱 통계량
분할 기준 사용
모든자료가 한 그룹에 있을 때
불수도 감소량이 아주 작을 때
최종노드가 너무 많으면->Overfitting 가능성이 커짐.
가지치기 규칙은 별도의 규칙을 제고할 수 있으며, 경험에 의해 실행할 수도 있음
목표변수가 연속형인 경우 F-검정통계량 OR 분산의 감소량을 분할기준 사용 의사결정나무 알고리즘 분류 및 기준변수의 선택법
이산형 목표변수 연속형 목표변수 CHAID 카이제곱 통계량 ANOVA F 통계량 CART 지니계수 분산 감소량 C5.0 엔트로피지수 의사결정나무의 장점 VS 단점
장점 단점 구조가 단순하여 해석이 용이하다. 분류기준값의 경계선 부근의 자료값에 대해서는 오차가 크다 선형성, 정규성, 등분산성 등의 수학적 가정이 불필요한 비모수적 모형 로지스틱회귀와 같이 각 예측변수의 효과를 파악하기 어렵다. 수치형/범주형 변수를 모두 사용할 수 있다는 점 새로운 자료에 대한 예측이 불안정할 수 있다. 앙상블 모형 배깅 VS 부스팅 VS 랜덤포레스트
배깅(bagging): 원데이터 집합으로부터 크기가 같은 표본을 여러 번 단순임의 복원추출하여 각 표본에 대해 분류기를 생성한 후 그 결과를 앙상블하는 방법이다. 반복추출 방법을 사용하기 때문에 같은 데이터가 한 표본에 여러번 추출될 수도 잇고, 어떤 데이터는 추출되지 않을 수도 있다.
부스팅(boosting): 배깅의 과정과 유사하나 붓스트랩 표본을 구성하는 sampling 과정에서 각 자료에 동일한 확률을 부여하는 것이 아니라, 분류가 잘못된 데이터에 더 큰 가중을 주어 표본을 추출한다.
랜덤포레스트(random forest): 배깅에 랜덤 과정을 추가한 방법이다. 각 노드마다 모든 예측변수 안에서 최적의 분할을 선택하는 방법 대신 예측변수들을임의로 추출하고, 추출된 변수 내에서 최적의 분항을 만들어 나가는 방법을 사용한다.
홀드아웃 VS 교차검증 VS 붓스트랩
홀드아웃 방법
주어진 원천 데이터를 랜덤하게 두 분류로 분리하여 쵸가 점정을 실시하는 방법으로 하나의 모형의 학습 및 구축을 위한 훈련용 자료로 하나는 성과 평가를 위한 검증용 자료로 사용한다. 홀드아웃 방법에서는 일반적으로 전체 데이터 중 70%의 데이터는 훈련용 자료로 사용하고 나머지는 검증용 자료로 사용한다.
교차검증(Cross Validation)
교차검증은 주어진 데이터를 가지고 반복적으로 성과를 측정하여 그 결과를 평균한 것으로 분류 분석 모형을 평가하는 방법이다. 대표적인 k-fold 교차검증은 전체 데이터를 사이즈가 동일한 k개의 하부집합으로 나누고 k번째의 하부집합을 검증용 자료로, 나머지 k-1개의 하부집합을 훈련용 자료로 사용, 이를 k번 반복 측정하고 각각의 반복측정 결과를 평균 낸 값을 최종 평가로 사용한다.
붓스트랩(Boostrap)
붓스트랩은 평가를 반복한다는 측면에서 교차검증과 유사하나 훈련용 자료를 반복 재선정한다는 점에서 차이가 있다. 즉 붓스트랩은 관측치를 한번 이상 훈련용 자료로 사용하는 복원추출법에 기반한다. 붓스트랩은 전체 데이터의 양이 크지 않은 경우의 모형 쳥가에 가장 적합하다.
오분류표를 활용한 평가 지표
매트릭 계산식 의미 Precision TP/(TP+FP) Y로 예측된 것중 실제로도 Y인 경우의 비율 Accuracy TP+TN/(TP+FP+FN+TN) 전체 예측에서 올은 예측의 비율 Recall(Sensitivity) TP/(TP+FN) 실제로 Y인 것들 중 예측이 Y로 된 경우의 비율 Specificity TN/(FP+TN) 실제로 N인 것들 중 예측이 N으로 도니 경우의 비율 FP Rate FP/(FP+TN) Y가 아닌데 Y로 예측된 비율
=(1-Specificity)
F1 2*[Precision*Recall/(Precision+Recall)] Precision과 Recall의 조화평균
시스템의 성능을 하나의 수치로 표현하기 위해 사용하는 점수로, 0~1사이의 값을 가진다.
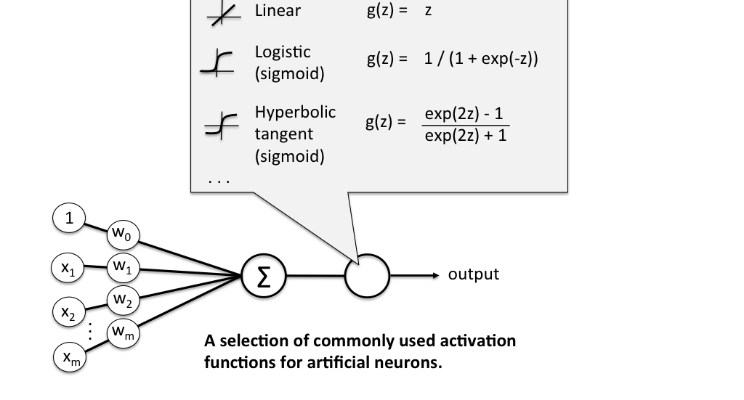
Kappa Accuracy-P(e)/(1-P(e)) 코헨의 카파는 두 평가자의 평가가 얼마나 일치하는지 평가하는 값으로 0~1사이의 값을 가진다. ROC(Receiver Operation Characteristic)
x축에는 FP ratio, y축에는 민감도를 나타내 이 두 평가 값의 관계로 모형을 평가한다.
ROC 그래프의 밑부분의 면적이 넓을수록 좋은 모형을 평가한다.
http://gim.unmc.edu/dxtests/roc3.htm 이익도표 VS 향상도 곡선
이익도표는 분류 분석 모형을 사용하여 분류된 관측치가 각 등급별로 얼마나 포함되는지를 나타내는 도표이다.
향상도 곡선(lift curve)은 랜덤 모델과 비교하여 해당 모델의 성과가 얼마나 향상 되었는지를 각 등급별로 파악하는 그래프이다.
군집화의 방법

계층적 군집의 거리 측정 정의
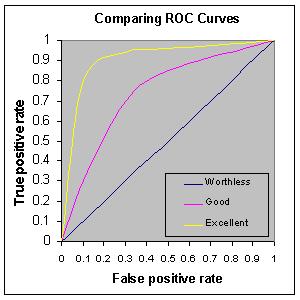
1. 유클리드(Euclidean distance): 두 점 사이의 거리로 가장 직관적이고 일반적인 거리 개념. 단 방향성이 고려되지 않은 단점이 있다.

https://ko.wikipedia.org/wiki/%EC%9C%A0%ED%81%B4%EB%A6%AC%EB%93%9C_%EA%B1%B0%EB%A6%AC 2. 맨하튼 거리: 두 점의 좌료 간의 절대값 차이를 구함. 맨하튼 격자 무늬 도로에서 유래
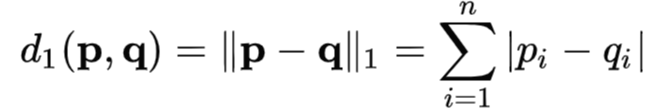
https://ko.wikipedia.org/wiki/%EB%A7%A8%ED%95%B4%ED%8A%BC_%EA%B1%B0%EB%A6%AC 3. 민코프스키(Minkowski) 거리: 가장 일반적으로 사용되는 Minkowski 거리의 차수는 1, 2,∞ p=2 이면 유클리드 거리, p=1이면 맨하튼 거리

4. 표준화 거리: 표준화 거리는 각 변수를 해당 변수의 표준편차로 척도 변환한 후에 유클리드 거리를 계산한 거리이다. 표준화를 하게 되면 척도의 차이, 분산의 차이로 인한 왜곡을 피할 수 있다. 표준화 거리는 다른 말로 통계적 거리라고도 한다.
5. 마할라노비스: 변수의 표준화와 함께 변수 간의 상관성을 동시에 고려한 통계적 거리로 생각할 수 있다.
계층적 군집의 특징
계층적 군집 방법은 군집을 혀성하는 데 매 단계에서 지역적 최적화를 수행해 나가는 방법을 사용하므로 그 결과가 전역적인 최적해라고 볼 수는 없다. 병합적 방법에서 한 번 군집이 형성되면 군집에 속한 개체는 다른 군집으로 이동 할 수 없다.
비계층적 군집(k-평균 군집)
1. 잡음이나 이상값에 영향을 받기 쉽다. 평균 대신 중앙값을 사용하는 k-medoids 군집을 사용할 수 있다. 또한 k-mean 분석 전에 이상값을 제거하는 것도 좋은 방법이다.
2. 계층적 군집과는 달리 k-mean 군집은 사전에 군집의 수를 정해주어야 한다. 만일 군집수 k가 원데이터 구조에 적합하지 않으면 좋은 결과를 얻을 수 없다. 따라서 Nbclust 패키지를 통해 군집의 수에 대한 정보를 참고해야 한다.
SOM(Self-Organizing Maps, 자기조직화지도)
차원축소와 군집화를 동시에 수행하는 기법인 자기조직화지도는 입력 벡터를 훈련집합에서 match 되도록 가중치를 조정되는 인공 시녕세포 격자에 기초한 자율학습의 한 방법이다.
SOM Process
단계 1: SOM 맵의 노드에 대한 연결강도로 초기화한다.
단계 2: 입력 벡터와 경쟁층 노드 간의 유크리드 거리 계산하여 입력벡터와 가장 짧은 노드를 선택한다.
단계 3: 선택된 노드와 이웃 노드의 가중치를 수정한다.
단계 4: 단계 2로 가서 반복하면서 연결가오는 입력 패턴과 가장 유사한 경쟁층 뉴런이 승자가 된다. 결국 승자 독식 구조로 인행 경쟁층에는 승자 뉴런만이 나타난다.
신경망은 역전파 알고리즘이지만 SOM는 전방패스를 사용하여 속도가 매우 빠르다.
SOM VS 신경망 모형
1. 신경망 모형은 연속적인 layer로 구성된 반면에 SOM은 2차원의 그리드로 구성
2. 신경망 모형은 에러를 수정하면서 학습하는 반면에 SOM은 경쟁학습을 실시
3. SOM 비지도학습
연관분석(Association Analysis)
연관규칙이란 항독들 간의 '조건-결과'식으로 표현되는 유용한 패턴을 말한다. 이러한 패턴 규칙을 발견해내는 것을 연관분석이라 하며, 흔히 장바구니 분석이라고 한다. 예를 들면 미국의 마트에서 기저위를 사는 고객은 맥주를 동시에 구매한다는 연관규칙을 알아냈다고 한다.
연관규칙의 측정지표
1. 지지도(Support): 전체 거래항목 중 상품 A와 상품 B를 동시에 포함하여 거래하는 비율을 의미한다. A->B라고 하는 규칙이 전체 거래 중 차지하는 비율을 통해 해당 연관 규칙이 얼마나 의미가 있는 규칙인지를 확인한다.
A와 B가 동시에 포함된 거래수 / 전체 거래 수
2. 신뢰도(Confidence): 상품 A를 포함하는 거래 중 A와 B가 동시에 거래되는 비중으로, 상품 A를 구매했을 때 상품 B를 구매할 확률이 어느 정도 되는지를 확인한다.
A와 B가 동시에 포함된 거래수 / A가 포함된 거래 수
3. 향상도(Lift): 상품 A의 거래 중 항목 B가 포함된 거래의 비율 / 전체 상품 거래 중 상품 B가 거래된 비율(A가 주어지지 않았을 때 B의 확률 대비 A가 주어졌을 때 B의 확률 증가 비율)
A와 B가 동시에 일어난 횟수 / A, B 가 독립된 사건일 때 A,B가 동시에 일어날 확률
향상도 값의 정의
품목 A, B 사이에 아무런 관계가 상호 관계가 없으면 향상도는 1이고 향상도가 1보다 높아질수록 연관성이 높다고 할 수 있다. 이것은 또한 향상도가 1보다 크면 이 규칙은 결과를 예측하는 데 있어서 우수하다는 것을 의미한다. 즉 향상도가 1보다 크면 서로 양의 관계로 품목B를 구매할 확률보다 품목 A를 구매한 후에 품목 B를 구매할 확률이 더 높다는 것을 의미한다. 당연히 향상도가 1이면 품목간에 연관성이 없다. 향상도가 음이면 두 품목이 서로 음의 상관관계를 의미한다.
Apriori 알고리즘이란
연관규칙의 대표적인 알고리즘이다. 현재도 많이 사용되고 있다. 기본 개념은 데이터들에 대한 발생 빈도를 시반으로 각 데이터 간의 연관관계를 밝히기 위한 방법이다.
연관분석의 장점과 단점
장점 단점 조건반응으로 표현되는 연관 분석의 결과를 이해하기 쉽다. 분석 품목 수가 증가하면 분석 계산이 기하급수적으로 증가 강력한 비목적성 분석 기법 너무 세부화된 품목을 가지고 연관규칙을 찾으려면 의미 없는 분석 결과가 도출 분석 계산이 간편하다. 상대적 거래량이 적으면 규칙 발견 시 제외되기 쉽다. 데이터의 정규성 검정 3가지
1. Q-Q plot
그래프를 그려서 정규성 가정이 만족되는지 시각적으로 확인하는 방법이다.
Q-Q plot은 대각선 참조선을 따라서 값들이 분포하게 되면 정규성을 만족한다고 할 수 있다. 만얃 한쪽으로 치우치는 모습이라면 정규성 가정에 위배되었다고 볼 수 있다.
2. Shapiro-Wilk test, 샤피로-윌크 검정
오차항이 정규분포를 따르는지 알아보는 검정으로, 회귀분석에서 모든 독립변수에 대해서 종목변수가 정규분포를 따르는지 알아보는 방법이다.
귀무가설: 정규분포를 따른다.
3. Kolmogorov-Smirnov test, 콜모고로프-스미노프 검정
자료의 평균/표준편차와 히스토그램을 표준정규분포와 비교하여 적합도를 검정한다.
p-value가 0.05보다 크면 정규성을 가정하게 된다.
군집분석(군집 간의 거리)
1. 중심연결법: 두 군집의 중심에 대한 거리로 정의한다.
2. 단일연결법: 두 군집에 속하는 거리 중 가장 짧은 거리를 두 군집 사이의 거리로 정의한다.
3. 완전연결법: 두 군집에 속하는 거리 중에서 가장 먼 거리를 두 군집의 거리로 정의한다.
4. 평균연결법: 두 군집에 속하는 대상들의 모든 가능한 거리를 계산하여 이에 대한 평균값을 두 군집 사이의 거리로 정의한다.
5. 왈드방법: 군집 내의 분산을 최소로 만들어주는 군집을 찾는 방법으로서 군집 내의 분산을 통제한다는 의미에서 분산방법이라 부르기도 한다.
데이터 타입에 따른 분석 기법
분석 기법을 적용하기 위해서는 각 변수를 독립변수, 종속변수로 구분하는 것이 유용
독립변수(X) 종속변수(Y) 적용 수치형 수치형 아버지 키로 아들 키 예측 범주형 수치형 수면제의 종류로 수면시간 차이 수치형 범주형 온도에 따라 거북이 암수 예측 범주형 범주형 가족규모 그룹에 따라 세탁기 크기 데이터 타입 대상 분석 기법(R 함수) 독립변수 종속변수 1개 범주형 수치형 평균비교 일표본 t 검정(t.test()) 2개 범주형 수치형 평균비교 1. 두 집단의 평균비교를 우해서는 등분산검정을한다. p값이 > 유의수준, 등분산 동일가정
2. t.test
*독립변수: 예)남/여
3개 범주형 수치형 평균비교 anova 분산분석
* 주의: 독립변수가 factor가 아니면 회귀분석과 같은 분석이 되므로 꼭 factor를 확인해야 한다
* 분산의 동질성 검정 F 분포 이용
범주형 범주형 1. 적합도 검정: 관측값들이 어떤 이론적 분포를 따르고 있는지
2. 독립성 검정: 서로 연관이 있는지
3. 동질성 검정: 관측값들이 정해진 범주 내에서 서로 비슷한지
* 모분산 가설검정 카이제곱분포 이용
수치형 수치형 상관계수
단순회귀
산점도
수치 or 범주 범주 로지스틱회귀분석 등분산 검정- 분산분석과 회귀분석 등 대부분의 통계 절차에서는 표본ㄷㄹ이 서로 다른 평균을 갖는 모집간에서 추출되었더라도 분산이 동일, 정규성이 있다고 가정한다.
등분산 가정 검정 방법으로 레빈의 검정 바틀렛 검정이 있다.
'Study > 자격증' 카테고리의 다른 글
[ADsP 정리] 2.데이터의 분석 기획 (0) 2020.02.27 [ADsP 정리] 1.데이터 이해 (0) 2020.02.24