-
Recommendation Systems: User-based Collaborative Filtering using N Nearest Neighbors[번역]Research/Personalized Recommender Systems 2020. 5. 31. 23:18
Recommendation Systems: User-based Collaborative Filtering using N Nearest Neighbors
Introduction
Collaborative Filtering은 추천시스템에서 널리 쓰이는 기술이며 연구 분야가 급격히 진화하고 있습니다. Memory-based 그리고 Model-based 이 두 방법이 가장 자주 사용됩니다.
이 글에서 우리는 memory-based 방법인 UB-CF(User-Based Collaborative Filtering)을 다룰 것입니다. UB-CF의 주된 아이디어는 비슷한 특징을 가진 사람들은 비슷한 취향이라는 것을 가정합니다. 예를 들어 친구 밥에게 영화를 추천 한다면, 밥이랑 당신이 많은 영화를 같이봤고 거의 비슷하게 평가 했다면, 앞으로도 비슷한 영화를 좋아할 것이라고 볼 수 있습니다.
UB-CF를 구현하고 Active user인 친구 밥이 좋아할 영화의 목록을 생성하겠습니다. 이 글의 동기는 알고리즘을 자세히 알아보고 UB-CF가 실제로 어떻게 작동하는지 이해하기 위해서 입니다. 이 글의 대부분의 내용은 Course on Coursera에서 영감을 받았습니다.
User-User Collaborative Filtering
이 방법은 요청된 사용자와 유사한 사용자를 식별하고 원하는 등급을 이러한 유사한 사용자 등급의 가중 평균으로 추정합니다.

우리는 MovieLens 데이터셋을 이용하여 추천할 것 입니다. 프로그래밍 언어로는 Python을 쓸 것이고 대부분의 데이터분석은 Pandas 라이브러리를 사용합니다. IDE로는 Jupyter notebook을 쓰겠습니다.
시작하기에 앞서 사용하는 라이브러리 목록을 알려 드리고자 합니다.
- Pandas
- Numpy
- sklearn
앞으로 돌아가서 추천의 콘셉트를 이해하겠습니다. 더 나은 이해를 위해 코드의 일부분과 출력을 두었습니다. ipynb 전체 파일은 블로그 끝부분에 있습니다.
Score function
사용자 u와 아이템 i를 입력매개 변수로 Score를 반환하는 개인화 되지않은 Collaborative Filtering(즉, 과거 사용자의 좋아요, 싫어요, 평가는 고려되지 않습니다)은 생각해내기 어렵지 않습니다. 이 함수는 사용자 u가 얼마나 강하게 아이템 i를 선호하는지 나타내는 점수를 출력합니다.
따라서 일반적으로 사용자와 비슷한 다른 사용자의 등급을 사용합니다. 이 모든 것은 나중에 자세히 설명할 것입니다. 지금까지 사용한 공식은 다음과 같습니다.
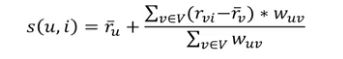
여기서 s는 예측한 Score이며, u는 사용자, i는 아이템, r는 사용자가 부여한 등급이며 w는 가중치입니다.
이 경우 우리의 점수는 각 사용자가 해당 항목에 대해 해당 사용자의 평균평점을 빼고 가중치를 곱한 가중치의 합과 같습니다. 이 가중치는 이 사용자가 얼마나 다른 사용자의 예측에 기여할 것인지에 대한 가중치입니다.
이것은 사용자 u와 v 사이의 가중치입니다. 점수는 0에서 1사이며 0은 가장 작은 값 1은 가장 큰 값입니다. 다 좋아 보이는데 그렇다면 왜 우리는 각 사용자 등급에 평균등급을 뺀 것이며, 왜 우리는 단순한 평균 대신 가중평균을 사용할까요?문제는 우리가 다루는 사용자의 유형에 있습니다. 사용자들은 종종 매우 다른 기준으로 평가한다는 사실에서 시작합니다. 내가 만일 점수를 주는데 후한 사람이라면 5점 만점에 4점을 줄 것입니다. 그러나 점수를 짜게 주는 사람은 5점 만점에 2점을 줄 것입니다. 후한 사람은 4점을 줬고 인색한 사람은 2점을 줬습니다. 이를 개선하기 위해선 사용자의 등급을 정규화 하면 이 알고리즘을 효율성을 증가시킬 수 있습니다. 그러기 위한 하나의 방법은 사용자가 각 항목에 주는 평균등급과 편차를 가지고 이 항목이 평균보다 얼마나 좋거나 나쁜지 계산하는 것입니다.
위 공식에서 주어진 가중치를 계산하기 위해 코사인 유사도를 사용했습니다. 그리고 우리가 진행하면서 이 블로그에서 논의될 이웃의 개념을 사용했습니다.
위 방식으로 데이터를 정규화하려면 Pandas에서 데이터 분석이 필요합니다. 코드 전체를 마지막에 볼 수 있으며 블로그에선 중요한 개념만 다루겠습니다.
import pandas as pd
movies = pd.read_csv("movies.csv",encoding="Latin1")
Ratings = pd.read_csv("ratings.csv")
Tags = pd.read_csv("tags.csv",encoding="Latin1")
Mean = Ratings.groupby(by="userId",as_index=False)['rating'].mean()
Rating_avg = pd.merge(Ratings,Mean,on='userId')
Rating_avg['adg_rating']=Rating_avg['rating_x']-Rating_avg['rating_y']
Rating_avg.head()

정규화된 등급 이제 사용자를 위한 정규화된 등급 계산을 했습니다. 위 데이터는 나중에 사용자의 최종 점수를 계산하는데 사용됩니다.
지금부터 추천 시스템과 관련된 중요한 개념에 집중하겠습니다.
Cosine Similarity
위 공식을 위해 우리는 비슷한 생각을 가진 사용자들을 찾을 필요가 있습니다. 비슷한 취향을 가진 사람을 찾는 것을 흥미로워 보입니다. 그러나 요점은'어떻게 비슷한 취향을 가진 사람을 찾는가?'입니다.
이것에 대한 대답은 코사인 유사도를 사용하는 것이며 어떻게 사용자가 비슷한지 볼 것입니다. 그것은 보통 두 사용자가 과거에 평가한 등급을 통해 계산됩니다.

우리의 예에서 유사성을 계산하기 위해 sklearn의 cosine_similarity를 사용했습니다. 그러나 그전에 전처리와 데이터 정리를 해야 합니다.
from sklearn.metrics.pairwise import cosine_similarity
final=pd.pivot_table(Rating_avg,values='adg_rating',index='userId',columns='movieId')

Pivot table 이 테이블에는 NaN 값이 많은데 모든 사용자들이 모든 영화를 보지 않았기 때문이며 이러한 행렬을 희소 행렬이라 합니다. Matrix factorization과 같은 방법은 이러한 희소성을 다루는데 사용되는데 이 글에서는 다루지 않겠습니다. 다음으로 NaN 값을 대체해야 하는 중요한 과정이 있습니다.
흔히 사용되는 두 가지 방법이 있습니다.
행의 평균을 사용하는 방법
열에 대한 평균을 사용하는 방법
저는 두 가지 방법 다 사용했고 아래의 코드에서 볼 수 있습니다. 설명을 위해서 행에 대한 평균을 사용하겠습니다.# Replacing NaN by Movie Average
final_movie = final.fillna(final.mean(axis=0))
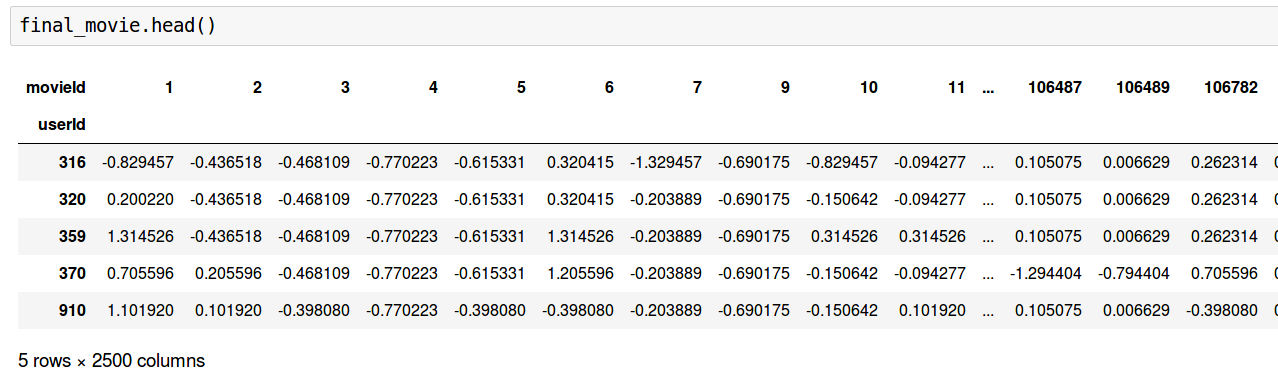
다음 단계로 사용자들 사이에 유사성을 계산합니다.
# user similarity on replacing NAN by item(movie) avg
cosine = cosine_similarity(final_movie)
np.fill_diagonal(cosine, 0 )
similarity_with_movie =pd.DataFrame(cosine,index=final_movie.index)
similarity_with_movie.columns=final_user.index
similarity_with_movie.head()

우리가 계산한 게 말이 되는지 확인해 봅시다!!
a = get_user_similar_movies(370,86309)
a = a.loc[ : , ['rating_x_x','rating_x_y','title']]
a.head()

Movies similar 위 그림에서 주어진 사용자(370, 86309)가 가진 등급이 우리가 생성한 등급과 거의 같음을 볼 수 있습니다.
사용자들 사이에서 유사성을 계산하는 끝났지만 아직 만족스럽지 않습니다. 다음 단계에서 그 이유를 설명해드리죠.
Neighborhood for User (K)
위에서 모든 사용자들의 유사성을 계산했습니다. 그러나 빅데이터 학도라서 문제의 복잡성이 항상 저를 자극합니다. 추천 시스템은 방대한 데이터와 함께 작동하므로 데이터에서 중요하고 필요한 하이라이트만 유지하고 캡처하는 것이 매우 중요합니다.
이를 영화 추천 시스템의 예를 사용하여 설명하기 위해 위에서 얻은 행렬은(862*862)로, 데이터에 862명의 고유한 사용자가 있기 때문입니다. 이 숫자는 실제 동작하는 시스템과 비교하여 작습니다. 아마존을 생각해 봅시다. 수백만 명의 사용자가 데이터베이스에 있으며 따라서 어떤 항목에 대한 점수를 계산하는 동안 다른 모든 사용자를 항상 보는 것은 좋은 해결책이나 방법이 아닐 것입니다. 이를 극복하기 위해 이 숫에 대한 개념을 생성합니다. 여기에는 특정 사용자에 대한(K) 유사한 사용자들 집합만 포함됩니다.
이 아이디어를 구현하기 위한 단계를 진행해 봅시다. 우리의 예에서 k의 값을 30으로 합니다. 따라서 모든 사용자에 대해 30명의 이웃을 가집니다.
유사도 행렬과 n의 값을 입력으로 받고 모든 사용자에 대해 가장 가까운 n 이웃을 반환하는 커스텀 함수 find_n_neighbors를 사용했습니다. 블로그 마지막에서 코드를 볼 수 있습니다.
# top 30 neighbours for each user
sim_user_30_m = find_n_neighbours(similarity_with_movie,30)
sim_user_30_m.head()

Top 30 neghbors for users 이제 불필요한 계산을 엄청나게 줄였습니다. 이제, 우리는 한 항목에 대한 점수를 계산할 준비가 됐습니다.
Generating the final score S(u,i)
이제 모든 과정을 했습니다. 기술적인 것을 다뤘지만, 마지막 단계에 가면 우리가 보낸 시간이 충분히 가치가 있습니다.
여기서 주어진 사용자가 보지 못한 영화의 점수를 예측하려고 합니다.
score = User_item_score(320,7371)
print(score)

predicted score 우리의 시스템은 점수를 4.25 예측했습니다. 사용자 370은 영화 7371을 좋아할 것입니다.
이제 우리 시스템의 마지막입니다. 여러분들은 대부분 넷플릭스와 같은 서비스를 사용했을 것입니다. 그래서 우리가 앱을 실행하면 당신이 좋아하는 아이템을 보여줍니다.
전 항상 그 추천에 끌립니다. 왜냐하면 그들이 내가 좋아하는 영화로 보이기 때문입니다. 이 모든 것은 추천 시스템 자체를 통해 일어납니다. 이제 우리는 사용자가 좋아할 수 있는 상위 5개의 영화를 예측하려고 할 것입니다.
로직이 그렇게 어렵지 않습니다. 우리는 이미 한 항목에 대한 등급을 생성했습니다. 마찬가지로 우리는 다른 항목에 대한 같은 사용자의 등급을 생성할 수 있습니다.
그러나 빅데이터라는 것을 다시 고려했을 때 모든 항목에 대한 점수를 생성하는 것이 좋을까요?
절대 아니죠!!!
사용자(U)와 사용자(K)를 고려해 봅시다. 이제 K가 U의 이웃이 아니라면 사용자 U가 K가 좋아하는 영화를 좋아할까요? 대부분 아닐 겁니다.
생각하셨나요? 아마도 우리는 사용자의 이웃이 본 영화의 등급을 계산하는 것에 관심이 있을 것입니다.성공적입니다. 우리는 계산을 2500에서 N으로 줄였고 2500보다 훨씬 적습니다.
이제 영화를 추천합시다.
User_item_score1은 사용자 정의함수인데 위에서 논의한 예측 계산을 사용합니다.user = int(input("Enter the user id to whom you want to recommend : "))
predicted_movies = User_item_score1(user)
print(" ")
print("The Recommendations for User Id : ",user)
print(" ")
for i in predicted_movies:
print(i)

드디어 해냈습니다. 우리는 우리만의 추천시스템을 만들었습니다.
설명에 쓴코드가 읽기 불편하기 때문에https://github.com/ashaypathak/Recommendation-system에서 코드를 볼 수 있습니다.
데이터셋은https://drive.google.com/drive/mobile/folders/1Nst6oCpxtkABJKq7qxtyhuCZcbp3Ltvo?usp=sharing여기서 얻을 수 있습니다.
'Research > Personalized Recommender Systems' 카테고리의 다른 글
[Recommeder System] 추천 시스템 - 관련 자료 및 사이트 정리 (0) 2020.08.28 ITEM2VEC: NEURAL ITEM EMBEDDING FOR COLLABORATIVE FILTERING 번역 (0) 2020.07.22 MATRIX FACTORIZATION TECHNIQUES FOR RECOMMENDER SYSTEMS 논문 리뷰 (0) 2020.06.12