-
MATRIX FACTORIZATION TECHNIQUES FOR RECOMMENDER SYSTEMS 논문 리뷰Research/Personalized Recommender Systems 2020. 6. 12. 00:08
Netflix Prize Competition에서 보여줬듯이 matrix factorization 모델은 전통적인 nearest-neighbor 보다 실제 상용 추천 에서 더 우수하며 implicit feedback(구매 내역, 검색 내역, 검색 패턴 등 사용자 패턴을 파악하는 간접적인 피드백), teporal effects, confidence levels(신뢰 구간)과 같은 추가 정보를 통합할 수 있습니다.
현대의 소비자들은 선택의 늪에 빠져있습니다. 전자 소매 업체 및 컨텐츠 제공자들은 오감을 만족시키는 새로운 기회를 가진 방대한 제품 선택권을 제공합니다. 가장 적합한 제품과 소비자를 매칭하는 것은 사용자의 만족감과 충성도를 향상시키는 핵심입니다. 그러므로 더 많은 소매업체들이 사용자의 취향에 맞는 개인화된 추천을 제공하기 위해 제품에 대한 사용자 관심 패턴을 분석하는 추천 시스템에 관심을 가지게 되었습니다.
훌륭한 개인화 추천은 사용자 경험에 또 다른 차원을 더할 수 있기 때문에 아마존이나 넷플릭스와 같은 e-commerce 리더들은 추천 시스템들을 그들의 웹사이트에서 중요한 부분으로 만들었습니다.
이러한 시스템은 영화, 음악, 그리고 티비쇼와 같은 엔터테인먼트 제품에 특히 유용합니다. 많은 고객들이 같은 영화를 볼 것이고, 각 고객들은 수많은 다른 영화를 볼 것 입니다.
고객들은 특정 영화에 대한 만족도를 나타낼 의사가 있기 때문에 어떤 영화가 고객에게 어필하는지에 대한 방대한 양의 데이터를 이용할 수 있습니다. 기업은 이 데이터를 분석하여 특정 고객에게 영화를 추천할 수 있습니다.
Recommender system strategies
널리 알려진 봐와 같이 추천시스템은 두개의 접근법에 기초하고 있습니다. Content filtering 접근 방식은 각각의 사용자 또는 제품의 특성을 구체화 하기 위해 프로필을 생성합니다. 예를 들어, 영화 프로필에는 장르, 참여 배우, 박스 오피스 인기 등에 관한 속성이 포함될 수 있습니다. 사용자 프로필에는 인구통계학적 정보나 답변이 포함될 수 있습니다. 이러한 프로필은 제품과 사용자를 매칭 시켜줄 수 있습니다. 물론 content-based strategies는 이용할 수 없거나 수집하기 쉬운 외부 정보를 수집해야 합니다.
Content filtering의 성공적인 예는 인터넷 라디오 서비스인 Pandora.com에 사용되는 Music Genome Project입니다. 훈련된 음악 분석가는 수백 가지의 뚜렷한 음악적 특징을 바탕으로 Music Genome Project에서 각 곡을 채점합니다. 이러한 속성 또는 유전자는 노래의 음악적 정체성뿐만 아니라 청취자의 음악적 선호도를 이해하는 것과 관련이 있습니다.
Content filtering의 대안은 explicit profiles 생성을 요구하지 않는 과거의 사용자 행동, 예를 들어 과거 트랜잭션 또는 제품 등급에만 의존하는 것 입니다. 이러한 접근은 collaborative filtering이라고 알려져 있으며, 최초의 추천 시스템인 Tapestry의 개발자들이 만든 용어입니다. collaborative filtering은 새로운 사용자와 항목의 연관성을 알아보기 위해 사용자와 품 간의 상호의존성 관계를 분석합니다. Collaborative filtering의 장점은 도메인 특성에 무관하다는 것입니다. Content filtering을 사용하여 파악하기 어렵고 프로파일링이 어려운 데이터의 측면을 다룰 수 있습니다. 일반적으로 content-based techniques 보다 정확하지만 collaborative filtering은 시스템의 신제품와 사용자를 다룰 수 없기 때문에 coldstart 라고 불리는 문제로 어려움을 겪습니다. 이러한 측면에서 content filtering이 더 우수합니다.

Figure 1 Collaborative filtering의 두 가지 주요 영역은 neighbor hood 방법과 latent factor 모델입니다. neighbor hood 방법은 항목 간의 관계 또는 사용자 간의 관계를 계산하는 데 중점을 둡니다. 아이템 중심의 접근법은 사용자의 선호도를 동일한 사용자가 ‘이웃’ 항목의 등급을 기준으로 항목에 대한 사용자의 선호도를 평가합니다. 제품의 이웃은 동일한 사용자가 평가할 때 비슷한 등급을 받는 경향이 있는 다른 제품입니다. 예를 들어 영화 ‘라이언 일병 구하기’가 있다면 이웃은 아마도 전쟁 영화, 스필버그의 영화, 톰행크스 출연 등일 것 입니다. ‘라이언 일병 구하기’의 등급을 예측하기 위해 우리는 이 사용자가 실제로 평가한 이 영화의 가장 가까운 이웃을 찾을 것입니다. 그림 1에서 알 수 있듯이 사용자 중심의 접근 방식은 서로의 등급을 보완할 수 있는 같은 생각을 가진 사용자를 식별합니다.
Latent factor 모델은 또 다른 접근법인데 등급 패턴에서 추론된 20에서 100개의 요인에 대한 아이템과 사용자 모두 특성화하여 등급을 설명합니다. 어떤 의미에서 이러한 factor는 상기 언급된 인간이 만든 노래 유전자에 대한 계산된 대안을 포함합니다. 영화의 경우, 발견된 factor들은 코미디 vs 드라마, 액션의 양, 시청연령 등과 같은 명백한 차원을 측정할 수 있습니다. 사용자에 대해 각 요인은 해당 영화 요인에서 높은 점수를 받은 영화를 얼마나 좋아하는지 측정합니다.
Figure 2는 2차원으로 단순화된 예에 대한 이 아이디어를 보여줍니다. 여성적인 것과 남성적인 것 그리고 심각한 것과 현실도피적인 것으로 특징지어지는 두 가지의 가상의 차원을 생각해 보겠습니다. 몇 개의 잘 알려진 영화들과 몇 명의 가상 사용자들이 이 두 가지 차원에 위치할 수 있는 곳을 보여줍니다. 이 모델의 경우, 영화의 평균 등급과 비교하여 영화에 대한 사용자의 예측 등급은 그래프의 영화 및 사용자의 위치의 내적과 동일합니다. 예를 들어 Gus는 Dumb and Dumber를 좋아하고 The Color Purple을 싫어하며 Braveheart의 등급은 평균일 것 입니다. 영화 Ocean’s 11과 사용자 데이브는 이 두 가지 차원에서 상당히 중립적인 것으로 특징지어질 것 입니다.
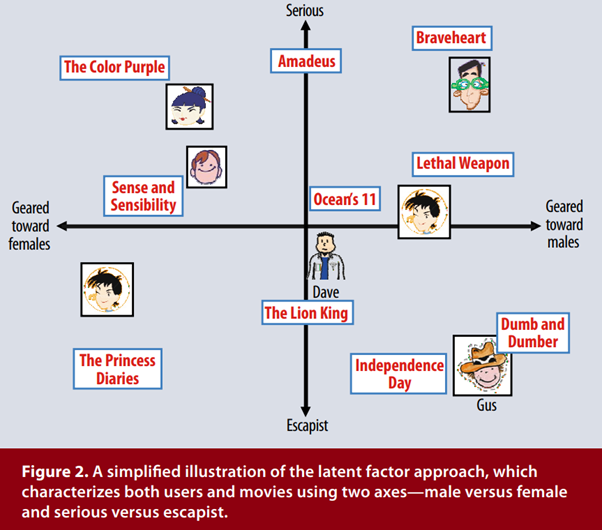
Figure 2 Matrix factorization methods
Latent factor model의 가장 성공적인 실현은 중 일부는 matrix factorization에 기반합니다. 기본 형식에서 matrix factorization은 아이템 등급 패턴에서 추론된 factor의 vector에 의해 아이템과 사용자 모두를 특성화합니다. 아이템과 사용자 factor 간의 높은 일치는 추천으로 이어집니다. 이러한 방법은 좋은 확장성과 예측 정확도를 결합하여 최근 몇 년 동안 인기를 얻었습니다. 또한 다양한 실행활 상황을 모델링하기 위해 많은 유연성을 제공합니다. 추천 시스템은 다른 유형의 입력 데이터에 의존하는데, 이는 종종 사용자를 나타내는 하나의 차원과 관심 항목을 나타내는 다른 차원을 가진 행렬에 배치됩니다. 가장 편리한 데이터는 사용자에 의해 제품에 대한 그들의 관심이 explicit한 입력을 포함하는 고품질의 explicit feedback입니다. 예를 들어 Netflix는 영화에 대한 별점을 수집하고 TiVousers는 좋아요 싫어요를 통해 TV 쇼에 대한 선호도를 표시합니다. 우리는 explicit user feedback을 등급으로 여깁니다. 일반적으로 explicit feedback은 sparse matrix를 포함합니다. 어떤 단일 사용자가 작은 확률로 아이템을 평가했을 가능성이 높기 때문입니다. Matrix factorization의 강점은 추가 정보를 통합할 수 있다는 것입니다. Explicit feedback을 사용할 수 없을 때 추천 시스템은 implicit feedback을 사용하여 사용자의 선호도를 추론할 수 있는데, 이는 구매 이력, 브라우징 이력, 검색 패턴 또는 마우스 움직임과 같은 사용자 행동을 관찰함으로써 간접적으로 관점을 반영합니다. Implicit feedback은 일반적으로 사건이 유/무를 나타내므로 일반적으로 densely filled matrix로 표시됩니다.
A BASIC MATRIX FACTORIZATION MODEL
Matrix factorization 모델은 사용자와 아이템을 차원 f의 joint latent factor 공간에 매핑하여 사용자와 아이템 상호 작용이 해당 공간에서 내적으로 모델링됩니다. 따라서 각 아이템 i는 f차원의 실수 공간에 벡터 $q_i$와 연관되며 각 사용자 u는 벡터 $p_u$와 연관됩니다. 아이템 i가 있을 경우 $q_i$의 요소는 아이템이 해당 factor를 소유하는 정도를 측정합니다. 사용자 u가 있을 경우 $p_u$의 요소는 해당 factor에 대해 높은 아이템에서 사용자가 갖는 관심의 정도를 긍정 혹은 부정으로 측정합니다. ${q_i}^T$ $p_u$의 dot product 결과는 사용자 u 그리고 아이템 i의 상호작용(사용자의 아이템 특성에 대한 전반적인 흥미)을 포착합니다. 사용자 u의 항목 i에 대한 등급을 근사하며, $r_ui$로 표시되어 추정치를 알려줍니다.

equation 1 주요한 문제는 각 아이템과 사용자의 매핑을 factor vector $q_i, p_u \in \mathbb{R}^f$ 로 계산하는 것입니다. 추천 시스템이 맵핑을 계산하고 나면, equation 1을 사용하여 사용자가 아이템에 부여할 등급을 쉽게 추정할 수 있습니다.
이러한 모델은 singular value decom-posiotion(SVD)와 밀접한 관련이 있으며, 정보 검색 분야에서 latent semantic factor를 식별하는데 쓰이는 기술로 정립되어 있습니다. SVD를 collaboratice filtering에 적용하는 것은 사용자 아이템 등급 행렬을 factoring(인수분해)해야 합니다. 이는 종종 사용자 아이템 등급 행렬의 희소성으로 인한 결측값이 많아서 어려움을 야기합니다. 기존의 SVD는 행렬에 대한 지식이 불완전할 때 정의되지 않습니다. 게다가, 비교적 적은 수의 알려진 항목들만 부주의하게 다루는 것은 overfitting될 수 있습니다. 이전 시스템은 누락된 등급을 채우고 행렬을 dense하게 만들기 위해 imputation(대치)에 의존했습니다.[2] 하지만 imputation은 데이터의 양이 증가하면 매우 비쌀 수 있습니다.
추가적으로 부정확한 imputation은 데이터를 많이 왜곡시킬 수도 있습니다. 그러므로 더 최근의 연구[3]-[6]들은 관측된 등급만을 직접 모델링하고 정규화된 모델을 통해 과적합을 피하는 것을 제안했다. factor vector를 얻기 위해 시스템은 알려진 등급 집합에 regularized squared error를 최소화합니다.

equation 2 여기서 k는 $r_ui$의 (u, i) 쌍의 집합입니다. 시스템은 이전에 관측된 등급을 fitting함으로써 학습합니다. 그러나 목표는 알려지지 않은 등급을 예측하는 방식으로 이전 등급을 일반화하는 것입니다. 따라서 시스템은 학습된 파라미터를 정규화하여 관측된 데이터를 overftting을 피해야 합니다. 상수 λ는 정규화의 정도를 제어하며 cross-validation에 의해 결정됩니다. Ruslan Salakhutdinov와 Andriy Mnih의 "Probabilistic Matrix Factorization"[7]은 정규화를 위한 확률론적 기초를 제공한다.
LEARNING ALGORITHMS
equation 2를 최소화하는 방법으로 stochastic gradient desent와 alternating least squares 두 가지가 있습니다.
Stochastic gradient descent
Simon Funk는 equation 2의 stochastic gradient desent 최적화를 대중화했으며, 알고리즘은 훈련 셋의 모든 등급을 순회합니다. 주어진 훈련 케이스 마다, 시스템은 $r_ui$를 예측하고 예측 오류를 계산합니다.

그런 다음 gradient의 반대 방향에서 $\gamma$에 비례하는 정도로 parameter를 수정하여 다음을 생성합니다.

이 인기 있는 접근법은 구현 용이성과 비교적 빠른 실행 시간을 가지고 있습니다. 그러나 어떤 경우에선 ALS 최척화를 사용하는 것이 도움이 됩니다.
Alternating least squares
$q_i$와 $p_u$ 모두 알 수 없기 때문에 equation 2는 convex가 아닙니다. 그러나 미지수 중 하나를 고정시키면 최적화 문제는 quadratic이 되어 해결할 수 있습니다. 따라서 ALS은 $q_i$를 고정하는 것과 $p_u$를 고정하는 것을 교대로 합니다. 모든 $p_u$가 fixed 됐을 때, 시스템은 $q_i$를 least-square problem으로 계산하며 반대로도 진행합니다. 이렇게 하면 각 단계는 수렴될 때까지 equation 2를 줄여나갈 수 있습니다.[8]
일반적으로 stochastic gradient descent가 ALS보다 쉽고 빠르지만 ALS는 적어도 두 가지 경우에서 유리한데 하나는 시스템이 병렬화를 사용할 수 있을 때입니다. ALS에서 시스템은 다른 아이템 factor와 독립적으로 각 $q_i$를 계산하고 다른 사용자 factor와 독립적으로 $p_u$를 계산합니다. 이로 인해 알고리즘의 대규모 병렬화가 야기됩니다.[9] 두 번째 경우는 implicit data에 초점을 둔 시스템을 위한 것입니다. 훈련 셋이 sparse하다고 볼 수 없기 때문에, gradient descent와 마찬가지로 각 단일 훈련 케이스를 looping하는 것은 실용적이지 못합니다. ALS는 이러한 경우에 효줄적으로 처리할 수 있습니다.
ADDING BIASES
Collaborative filtering에 대한 matrix factorization 접근법의 한 가지 이점은 다양한 데이터 측면 및 기타 응용 프로그램 특정 요구사항을 다루는 유연성입니다. 이것은 같은 학습 framework 안에서 equation 1을 수용해야 합니다. equation 1은 사용자와 다른 등급 값을 생성하는 아이템 간의 상호 작용을 담아내려고 합니다. 그러나 등급 값에서 관찰된 대부분의 variation은 어떤 상호 작용과는 무관하게 사용자 또는 아이템과 관련된 biases와 intercepts 때문입니다. 예를 들어 일반적인 collaborative filtering data는 일부 사용자가 다른 사용자보다 높은 등급을 주고 일부 아이템은 다른 사용자보다 높은 등급을 받는 경향이 있습니다. 결국엔 일부 product이 다른 product보다 더 나은(또는 더 나쁜) 것으로 받아 들여집니다.
따라서 ${q_i}^T p_u$의 형식의 관계로 전체 등급 값을 설명하는 것은 좋지 못합니다. 대신, 시스템은 개별 사용자 또는 아이템의 biases가 설명할 수 있는 값의 일부를 알아내려고 시도하며 데이터의 진정한 intersection만 factor modeling에 적용합니다. $r_ui$ 등급에 포함된 biases의 1차 근사치는 다음과 같습니다.

equation 3 $r_ui$ 등급에 포함된 biases는 $b_ui$라고 표시되며 사용자와 아이템 효과로 설명합니다. 전체 평균 등급은 $u$로 표시되고 parameter $b_u$ 그리고 $b_i$는 각각 평균으로부터 사용자 u 그리고 아이템 i의 관측된 편차를 나타냅니다. 예를 들어 영화 타이타닉에 대한 사용자 조의 등급의 1차 추정치를 원한다고 가정하겠습니다. 그리고 모든 영화들의 평균 등급, $u$가 별점 3.7입니다. 게다가 타이타닉은 평균 영화보다 높고 평균보다 별점 0.5 받는 경향이 있습니다. 반면에 조는 비판적인 상요자라서, 평균보다 0.3개의 별을 낮게 평가하는 경향이 있습니다. 그러므로 조의 타이타닉 등급에 대한 추정은 별점 3.9(3.7+0.5-0.3)일 것입니다. Biases는 다음과 같이 equation 1을 확장합니다.

equation 4 관측된 등급은 4개의 구성요소(글로벌 평균, 아이템 bias, 사용자 bias, 사용자-아이템 상호작용)으로 나뉩니다. 이를 통해 각 구성 요소는 해당 signal 부분만 설명할 수 있습니다. 시스템은 squared error function을 minimizing함으로써 학습합니다.[4][5]

equation 5 Biases는 관측된 signal의 많은 부분을 capture하는 경향이 있기 때문에 정확한 모델링이 중요합니다. 따라서, 다른 연구들은 더 정교한 모델을 제공합니다.[11]
ADDITIONAL INPUT SOURCES
종종 시스템은 cold start 문제를 다루어야 하는데, 많은 사용자들이 등급을 거의 공급하지 않아 그들의 취향에 대한 일반적인 결론에 도달하기 어렵습니다. 이 문제를 해결하는 방법은 사용자에 대한 추가 정보 소스를 결합하는 것입니다.
Recommander system은 사용자 선호도에 대한 통찰력을 얻기 위해 implicit feedback을 사용할 수 있습니다. 실제로 explicit 등급을 제공하려는 사용자의 의지에 관계없이 행동 정보를 수집할 수 있습니다. retailer는 고객이 제공하는 등급 외에 고객의 구매 또는 검색 내역을 사용하여 고객의 성향을 알 수 있습니다.
간단하게 Boolean implicit feedback이 있는 경우를 고려해보겠습니다. N(u)는 사용자 u가 implicit 선호도를 표현한 아이템 집합을 나타냅니다. 이렇게 하면, 시스템은 사용자가 implicitly preferred하는 아이템을 통해 사용자를 프로파일링합니다. 여기서 새로운 아이템 factor의 set이 필요하며, 아이템 i는 $x_i \in \mathbb{R}^f$ 와 연관됩니다. 따라서 N(u)에서 아이템에 대한 선호도를 나타낸 사용자는 vector에 의해 characterized됩니다.

vector Sum을 nomalizing하는 것은 종종 도움이 됩니다. 예를 들면 아래와 같이

또 다른 information sources는 인구 통계학과 같은 알려진 사용자의 속성입니다. 다시 말하자면, 사용자 u의 성별, 연령대, 주소, 소득 수준 등을 설명할 수 있는 속성 A(u)의 집합에 해당하는 Boolean 속성을 고려하는 것입니다. distinct vector factor $y_a \in \mathbb{R}^f$는 사용자와 관련된 속성 집합을 통해 사용자를 설명하기 위한 각 속성에 해당합니다.
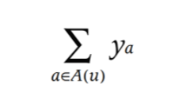
Matrix factorization 모델은 모든 signal source를 통합해야 합니다.

이전의 예들은 데이터가 부족할 때 user representation을 향상시키는 것을 다뤘지만 아이템도 필요하다면 비슷한 처리를 할 수 있습니다.
TEMPORAL DYNAMICS
지금까지 말한 모델은은 static합니다. 실제로 product perception과 popularity는 새로운 선택이 나타나면서 계속해서 변합니다. 마찬가지로 고객의 성향도 변하고 취향을 재정의하게 됩니다. 따라서 시스템은 사용자 아이템 상호작용의 동적이고 시간적인 특성을 반영하는 temporal effect를 고려해야 합니다. Matrix factorization접근법은 temporal effect를 모델링하는데 좋으며 정확도를 크게 향상시킬 수 있습니다. 등급을 별개의 term으로 분해하면 시스템이 다른 temporal 측면을 별도로 처리할 수 있습니다. 구체적으로 다음 용어는 시간에 따라 다양합니다. 아이템 biasese bi(t), 사용자 biases bu(t), user preference pu(t).
첫 번째 temporal effect는 한 항목의 인기가 시간이 지남에 따라 변할 수 있다는 사실을 다룹니다. 예를 들어 영화는 배우의 새로운 영화에 출연하는 것과 같은 외부 사건에 의해 인기를 얻을 수 있습니다. 따라서 이러한 모델은 아이템 bias를 시간의 함수로 취급합니다. 두 번째 시간 효과는 사용자가 시간이 지남에 따라 기준 등급을 변경할 수 있게 해줍니다. 예를 들어, 평균적인 영화 "4개의 별"을 평가하는 경향이 있는 사용자는 이제 그 영화 "3개의 별"을 평가할 수 있습니다.
이는 시간이 지남에 따라 rater's의 indentity가 바뀔 수 있다는 사실을 포함한 몇가지 factor를 반영할 수 있습니다. 따라서 이러한 모델에서 parameter $b_u$는 시간의 함수입니다.
temporal dynamics는 사용자 선호도와 사용자와 아이템 간의 상호 작용에도 영향을 미칩니다. 사용자들은 시간이 지남에 따라 자신의 선호도를 바꿉니다. 예를 들어 심리 스릴러 장르의 팬은 1년 뒤에 범죄 드라마를 좋아할 수 있습니다. 마찬가지로 사용자는 특정 배우와 감독에 대한 인식을 바꿀 수 있습니다. 이 모델은 사용자 factor(vector $p_u$)를 시간의 함수로 삼아 이러한 효과를 설명합니다. 반면에 아이템의 경우 정적인 특성으로 정의합니다. 왜냐하면 사람과 달리 아이템 자체는 변하지 않기 때문입니다. 시간에 의해 변하는 parameter의 정확한 매개변수화는 시간 t에서 등급을 동적으로 예측하는 방식으로 equation 4를 대체합니다.

equatuion 7 INPUTS WITH VARYING CONFIDENCE LEVELS
여러가지 setup을 통해 관찰된 모든 등급이 동일한 가중치나 신뢰를 가지진 않습니다. 예를 들어 대규모 광고는 장기적인 특성을 반영하지 않고 특정 아이템의 투표에 영향을 줄 수 있습니다. 반대로 시스템은 특정 아이템을 나쁘게 평가하려는 사용자도 만날 수 있습니다.
또 다른 예는 implicit feedback을 가지고 구축된 시스템입니다. 이러한 시스템은 사용자의 행동을 해석하는 것이라, 사용자의 선호도를 정확하게 정량화 하여 측정하기 어렵습니다. 따라서, 시스템은 "제품을 좋아할 가능성이 있다" 또는 "제품에 관심이 없을 가능성이 있다" 와 샅은 상태를 미숙한 binary representation으로 작동합니다. 이 경우, 추정된 선호도와 신뢰 점수를 첨부하는 것이 중요합니다. 신뢰도는 action의 frequency를 설명하는 수치적인 값으로 얻을 수 있습니다. 예를 들어, 사용자가 특정 쇼를 얼마나 많이 봤는지 또는 사용자가 특정 아이템을 얼마나 자주 구입했는지를 확인합니다. 이러한 수치는 각 관측에 대한 신뢰도를 나타냅니다. 사용자 선호도와 무관한 다양한 factor는 일회성 이벤트를 일으킬 수 있습니다. 그러나 반복되는 이벤트는 사용자 선호를 반영할 가능성이 더 큽니다. Matrix factorization 모델은 다양한 신뢰 수준을 쉽게 적용할 수 있으며, 이는 덜 의미 있는 관측에 가중치를 덜 줄 수 있게 해줍니다. 만약 $r_ui$에서 관측된 신뢰도를 $c_ui$와 같이 표시한다면, 모델은 신뢰도를 설명하기 위해 equation 5의 cost function을 아래와 같이 설명합니다.

equation 8 이러한 것과 관련된 실제적으로 적용된 애플리케이션에 대한 정보는 “Collaborative Filtering for Implicit Feedback Datasets.”[10]을 참고하시면 됩니다.
NETFLIX PRIZE COMPETION
2006년 온라인 DVD 대여 회사인 Netflix는 추천 시스템을 개선하기 위한 콘테스트를 발표했습니다.[12] 이를 위해 익명의 고객 50만여 명에 달하는 1억 개 이상의 등급과 1만7000여 편의 영화에 대한 등급을 담은 학습 셋을 공개했는데, 각 영화는 별 1~5개로 평가됐습니다. 참여팀은 약 300만 개의 등급으로 구성된 테스트 세트에 대해 예측한 등급을 제출하고, 넷플릭스는 held-out truth를 바탕으로 root mean square error(RMSE)를 계산합니다. 넷플릭스 알고리즘의 RMSE 성능을 10% 이상 향상시킬 수 있는 첫 번째 팀은 100만 달러의 상금을 받습니다. 만약 어떤 팀도 10%의 목표에 도달하지 못한다면, Netflix는 경기의 해마다 1위 팀에게 5만 달러의 프로그레시브 상을 줍니다. 이 대회는 collaborative filtering 분야에서 화제가 되었습니다. 이전까지는 collaborative filtering을 연구하기 위한 데이터셋의 규모는 작았습니다. 이 데이터의 공개와 대회의 매력이 연구에 대한 열정에 트리거가 되었습니다. 182개국의 4만 8000개 이상의 팀들이 이 데이터를 다운로드 했다고 합니다.
BellKor라 불리는 우리 팀이 대회에 나가서 2007년 여름에 1등을 차지했고, 당시 최고 점수인 넷플릭스보다 8.43% 더 좋은 성능을 보여 프로그레시브 상을 받았습니다. 나중에 Big Chaos 팀과 같이 2008년 프로그레시브 상을 9.46%의 점수로 수상하였습니다. 이 글을 쓸 당시 우리는 10%에 거의 도달해 갑니다.

Figure 3 당첨 된 출품작은 100 개 이상의 서로 다른 예측 변수 셋으로 구성되며, 대부분 예측 변수 셋은 여기에 설명 된 방법의 일부 변형을 사용하는 factorization models입니다. 다른 최고 팀들과의 토론과 공개 경연 포럼에 올린 글들은 이것이 등급을 예측하는 가장 인기 있고 성공적인 방법이라는 것을 보여줍니다. 넷플릭스 사용자 영화 행렬을 factorization 하면 영화 선호도를 예측을 위한 가장 설명적인 차원을 발견할 수 있습니다. 우리는 matrix factorization으로부터 처음 몇 가지 중요한 차원을 식별하고 이 새로운 공간에서 영화의 위치를 탐구할 수 있습니다. Figure 3은 넷플릭스 데이터 matrix factorization에서 처음 두 가지 factor를 보여줍니다. 영화는 그들의 factor vector에 따라 배치됩니다. 보여진 영화에 익숙한 사람은 latent factor에서 명확한 의미를 볼 수 있다.
첫 번째 factor x 축은 저속한 코미디나 공포영화로 남성 또는 청소년을 대상으로 하고 반대편은 진지하고 여성성이 강한 드라마나 코미디를 담고 있습니다. 두 번째 factorization은 y축과 독립적이고 비평가들에게 호평을 받고 기이한 영화는 꼭대기(Punch-Drunk Love, I Heart Huckabees)에 있습니다. 아래에는 주류의 영화(아마겟돈, 러너웨이 브라이드)가 있습니다. 이 경계 사이에는 흥미로운 교차점이 있는데 왼쪽 상단 모서리에는 Kill Bill과 Natural Born Killers가 있는데 둘 다 폭력적인 주제를 다루는 예술 영화입니다. 오른쪽 하단에는 여성 중심의 진지한 영화면서 주류인 The Sound of Music이 있습니다. 그리고 중간에 모든 사람들에게 어필이 되는 The Wizard of Oz가 있습니다.
이 plot에서 서로 인접한 일부 영화는 보통 함께 배치되지 않습니다. 예를 들어, Annie Hall과 Citizen Kane은 서로 옆에 있습니다. 스타일적으로 매우 다르지만, 유명한 감독들에 의해 고전적인 영화로 널리 알려져 있습니다. 실제로, factorization의 세 번째 차원은 이 두 가지를 분리하는 것으로 끝납니다.

Figure 4 Factorization을 위해 많은 구현과 매개변수화를 시도했습니다. Figure 4는 다른 모델과 파라미터 수가 RSME에 어떠한 영향을 미치는지 그리고 biases 추가, implicit feedback 사용, temporal dynamics를 추가하면서 변형을 보여주고 있습니다. 각 factor 모델의 정확도는 관련 매개변수의 수를 증가시킴으로써 향상되는데, 이는 차트의 숫자로 표시된 요인 모형의 차수를 증가시키는 것과 같습니다.
설명이 더 명확한 매개 변수 셋을 포함하는 더 복잡한 fator 모델이 더 정확합니다. 실제로, temporal component는 데이터에 상당한 시간적 영향이 있기 때문에 모델링에 특히 중요합니다.
Matrix factorization은 collaborative filtering에서 지배적 인 방법론이되었습니다. Netflix Prize 데이터와 같은 데이터 세트를 경험한 결과, 고전적인 근접 기술보다 정확성이 우수하다는 것을 알 수 있었습니다. 동시에, 시스템이 비교적 쉽게 배울 수 있는 컴팩트한 메모리 효율 모델을 제공합니다.이러한 기술을 더욱 편리하게 만드는 것은 모델이 여러 형태의 피드백, temporal dynamics 및 confidence levels과 같은 데이터의 많은 중요한 측면을 자연스럽게 통합할 수 있다는 것입니다.
References
1. D. Goldberg et al., “Using Col- laborative Filtering to Weave an Information Tapestry,” Comm. ACM, vol. 35, 1992, pp. 61-70.
2. B.M. Sarwar et al., “Application of Dimensionality Reduction in Recommender System—A Case Study,” Proc. KDD Workshop on Web Mining for e-Commerce: Challenges and Opportunities (WebKDD), ACM Press, 2000.
3. S. Funk, “Netflix Update: Try This at Home,” Dec. 2006; http://sifter.org/~simon/journal/20061211.html.
4. Y. Koren, “Factorization Meets the Neighborhood: A Multifaceted Collaborative Filtering Model,” Proc. 14th ACM SIGKDD Int’l Conf. Knowledge Discovery and Data Mining, ACM Press, 2008, pp. 426-434.
5. A. Paterek, “Improving Regularized Singular Value Decomposition for Collaborative Filtering,” Proc. KDD Cup and Workshop, ACM Press, 2007, pp. 39-42.
6. G. Takács et al., “Major Components of the Gravity Recommendation System,” SIGKDD Explorations, vol. 9, 2007, pp. 80-84.
7. R. Salakhutdinov and A. Mnih, “Probabilistic Matrix Factorization,” Proc. Advances in Neural Information Processing Systems 20 (NIPS 07), ACM Press, 2008, pp. 1257-1264.
8. R. Bell and Y. Koren, “Scalable Collaborative Filtering with Jointly Derived Neighborhood Interpolation Weights,” Proc. IEEE Int’l Conf. Data Mining (ICDM 07), IEEE CS Press, 2007, pp. 43-52.
9. Y. Zhou et al., “Large-Scale Parallel Collaborative Filtering for the Netflix Prize,” Proc. 4th Int’l Conf. Algorithmic Aspects in Information and Management, LNCS 5034, Springer, 2008, pp. 337-348.
10. Y.F. Hu, Y. Koren, and C. Volinsky, “Collaborative Filtering for Implicit Feedback Datasets,” Proc. IEEE Int’l Conf. Data Mining (ICDM 08), IEEE CS Press, 2008, pp. 263-272.
11. Y. Koren, “Collaborative Filtering with Temporal Dynamics,” Proc. 15th ACM SIGKDD Int’l Conf. Knowledge Discovery and Data Mining (KDD 09), ACM Press, 2009, pp. 447-455.
12. J. Bennet and S. Lanning, “The Netflix Prize,” KDD Cup and Workshop, 2007; www.netflixprize.com.
Yehuda Koren is a senior research scientist at Yahoo Research, Haifa. His research interests are recommender systems and information visualization. He received a PhD in computer science from the Weizmann Institute of Science. Koren is a member of the ACM. Contact him at yehuda@yahoo-inc.com.
Robert Bell is a principal member of the technical staff at AT&T Labs—Research. His research interests are survey research methods and statistical learning methods. He received a PhD in statistics from Stanford University. Bell is a member of the American Statistical Association and the Institute of Mathematical Statistics. Contact him at rbell@ research.att.com.
Chris Volinsky is director of statistics research at AT&T Labs—Research. His research interests are large-scale data mining, social networks, and models for fraud detection. He received a PhD in statistics from the University of Washington. Volinsky is a member of the American Statistical Association. Contact him at volinsky@research.att.com.
'Research > Personalized Recommender Systems' 카테고리의 다른 글